DataCrunch Blog

NEW News
DataCrunch is Launching Two Communities for AI Builders

NEW GPU comparison
NVIDIA B300 vs. B200: Complete GPU comparison to date

DataCrunch Raises $64M in Series A
News

The DataCrunch Stack: Optimizing the AI Cloud for efficiency and portability
Technical analyses

Revolutionizing marine mammal research with AI-powered photo identification
Customer stories

How Simli Achieved Cost-Efficient, Real-Time Inference for Interactive AI Avatars
Customer stories

DataCrunch-Latvian Alliance Submits Proposal for EU's AI GigaFactory
News

Data Movement in NVIDIA's Superchip Era: MEMCPY Analysis from Grace Hopper GH200
Benchmarks

Pyxis and Enroot Integration for the DataCrunch Instant Clusters
Guides

How Freepik scaled FLUX media generation to millions of requests per day with DataCrunch and WaveSpeed
Customer stories

Multi-Head Latent Attention: Benefits in Memory and Computation
Benchmarks

FLUX on B200 vs H100: Real-Time Image Inference with WaveSpeedAI
Benchmarks

DeepSeek-V3 + SGLang: Inference Optimization
Technical analyses

DeepSeek + SGLang: Multi-Head Latent Attention
Technical analyses

Multi Data Center Training: Prime Intellect
Technical analyses

Deploy DeepSeek-R1 671B on 8x NVIDIA H200 with SGLang
Guides

DeepSeek V3 LLM NVIDIA H200 GPU Inference Benchmarking
Benchmarks
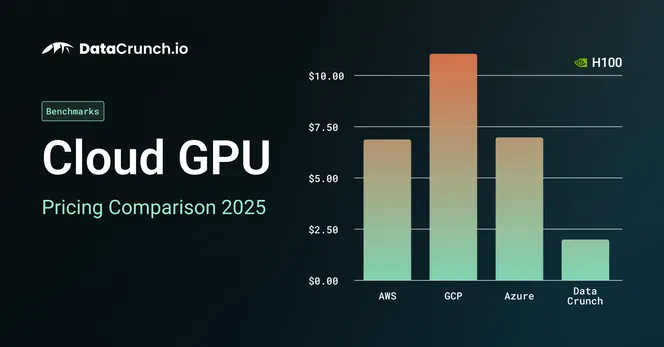
Cloud GPU Pricing Comparison in 2025
GPU comparison

DataCrunch Leads Europe in Deploying NVIDIA’s New H200 GPUs
News

DataCrunch.io Secures $13 Million Seed Round to Transform AI Computing
News

NVIDIA H200 vs H100: Key Differences for AI Workloads
Legacy

NVIDIA GB200 NVL72 for AI Training and Inference
Legacy
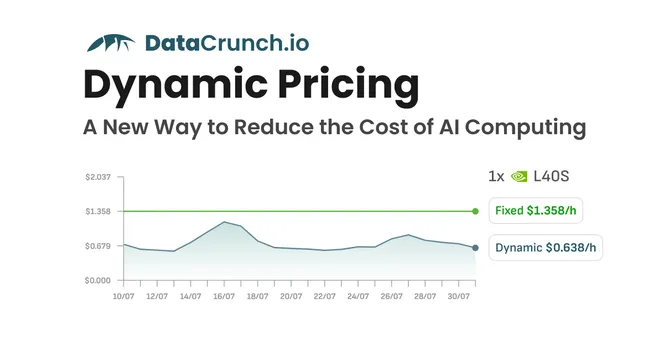
Introducing Dynamic Pricing for Cloud GPU Instances – A New Way to Reduce the Cost of AI Computing
News

PCIe and SXM5 Comparison for NVIDIA H100 Tensor Core GPUs
Legacy

NVIDIA H200 – How 141GB HBMe and 4.8TB Memory Bandwidth Impact ML Performance
Legacy

NVIDIA Blackwell B100, B200 GPU Specs and Availability
Legacy

NVIDIA A100 GPU Specs, Price and Alternatives in 2024
Legacy

NVIDIA A100 PCIe vs SXM4 Comparison and Use Cases in 2024
Legacy

NVIDIA A100 40GB vs 80 GB GPU Comparison in 2024
Legacy

A100 vs V100 – Compare Specs, Performance and Price in 2024
Legacy

NVIDIA H100 GPU Specs and Price for ML Training and Inference
Legacy
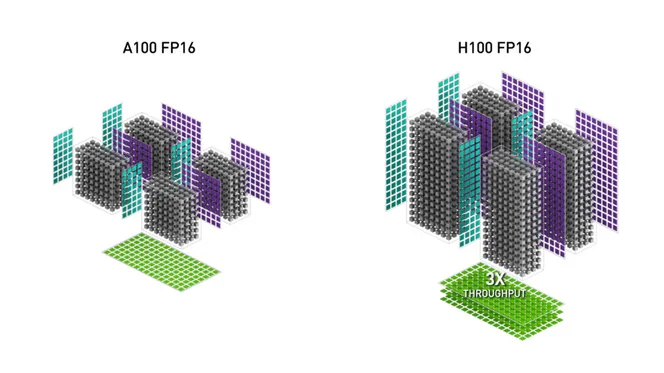
NVIDIA H100 vs A100 GPUs – Compare Price and Performance for AI Training and Inference
Legacy