
Even today, the NVIDIA A100 Tensor Core remains one of the most powerful GPUs that you can use for AI training or inference projects. While it has been overtaken in pure computational power by the H100 and the H200, the A100 offers an excellent balance of raw compute, efficiency and scalability.
While it was initially in short supply, availability of the A100 has improved over the past year and today you can get access to both versions of the A100, a 80GB and 40GB model through Cloud GPU platforms like DataCrunch. Let’s go through what you need to know about the difference of these two models is in specs, performance and price.
Understanding the NVIDIA Ampere Architecture
The NVIDIA A100 GPU is built on the Ampere architecture, a significant leap in GPU design, engineered to meet the rigorous demands of AI and high-performance computing (HPC). Here’s what sets the Ampere architecture apart:
Third-Generation Tensor Cores The Ampere architecture introduces third-gen Tensor Cores, delivering up to 20x higher performance for AI workloads compared to its predecessors. These cores support new data types like TF32 for training and FP64 for HPC, enabling faster computations without compromising precision.
Multi-Instance GPU (MIG) Technology A hallmark of Ampere, MIG allows a single A100 GPU to be split into up to seven independent GPU instances. Each instance operates with its own resources, providing optimal utilization for mixed workloads and shared environments.
High-Bandwidth Memory (HBM2e) The A100 leverages HBM2e memory, providing a memory bandwidth of up to 1.6 TB/s. This ensures that large datasets and complex models can be processed efficiently, reducing bottlenecks in memory-intensive tasks.
Sparse Matrix Acceleration Ampere introduces structural sparsity, a feature that doubles the performance of Tensor Core operations by leveraging sparse data structures. This is particularly useful for AI models where sparsity can be exploited without impacting accuracy.
Scalable Performance Designed for scale, the Ampere architecture works seamlessly in multi-GPU setups, especially when combined with technologies like NVLink and NVSwitch. This makes the A100 an excellent choice for data center deployments requiring high throughput.
This architecture forms the backbone of the NVIDIA A100's capabilities, making it a versatile solution for both training and inference in AI, as well as for scientific simulations and other demanding computations.
A100 40GB vs 80GB Comparison
Feature | A100 40GB | A100 80GB |
|---|---|---|
Memory Configuration | 40GB HBM2 | 80GB HBM2e |
Memory Bandwidth | 1.6 TB/s | 2.0 TB/s |
Cuda Cores | 6912 | 6912 |
SMs | 108 | 108 |
Tensor Cores | 432 | 432 |
Transistors | 54.2 billion | 54.2 billion |
Power consumption | 400 Watts | 400 Watts |
Launch date | May 2020 | November 2020 |
*See a more detailed outline of A100 specs.
Memory Capacity
The obvious difference between the 40GB and 80GB models of the A100 is their memory capacity. By doubling memory capacity, the 80GB model is ideal for applications requiring substantial memory, such as large-scale training and inference of deep learning models. The increased memory allows for larger batch sizes and more extensive datasets, leading to faster training times and improved model accuracy.
Memory Bandwidth
The memory bandwidth also sees a notable improvement in the 80GB model. With 2.0 TB/s of memory bandwidth compared to 1.6 TB/s in the 40GB model, the A100 80GB allows for faster data transfer and processing. This enhancement is important for memory-intensive applications, ensuring that the GPU can handle large volumes of data without bottlenecks.
Common use cases for the A100 40GB
The 40GB version of the A100 is well-suited for a wide range of AI and HPC applications. It provides plenty of memory capacity and bandwidth for most workloads, enabling efficient processing of large datasets and complex models.
Standard AI Training: The 40GB A100 is suitable for training models that fit within its memory limit, which still includes many applications in computer vision and natural language processing. Its high bandwidth ensure efficient handling of substantial datasets and complex models without bottlenecks.
Inference: The 40GB A100 offers sufficient memory and performance to handle real-time inference tasks across various AI applications, from image recognition to language translation.
Data Analytics: The 40GB version is also suitable for data analytics workloads, where it can process large datasets quickly.
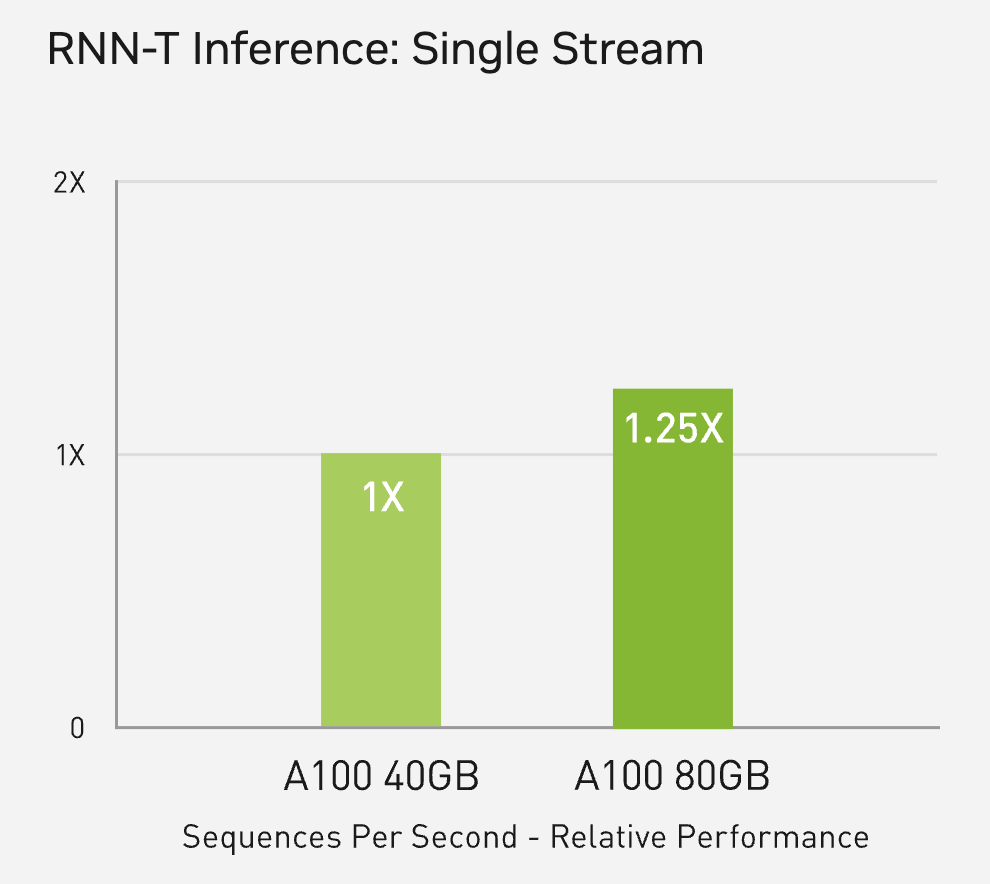
For RNN-T Inference, the performance of the 40GB and 80GB A100 were comparable. (Source: nvidia.com)
Common use cases for the A100 80GB
The 80GB version of the A100 doubles the memory capacity and increases the memory bandwidth to 2 TB/s. This configuration is particularly beneficial for compute-hungry AI applications that involve larger models and datasets, such as natural language processing (NLP) and scientific simulations. The additional memory capacity and bandwidth enable faster data transfer and processing, reducing training times and improving overall performance. The increased memory capacity and bandwidth of the 80GB A100 have several performance implications:
Larger Models: For the largest ML models, such as DLRM, the 80GB model reaches up to 1.3TB of unified memory per node and delivers up to a 3x throughput increase over the 40GB.
Faster Processing: The higher memory bandwidth enables faster data transfer between the GPU and memory, leading to quicker computations and reduced training times.
Multi-Tasking: With more memory, the 80GB A100 can efficiently manage multiple tasks simultaneously, making it ideal for complex, multi-faceted workloads.
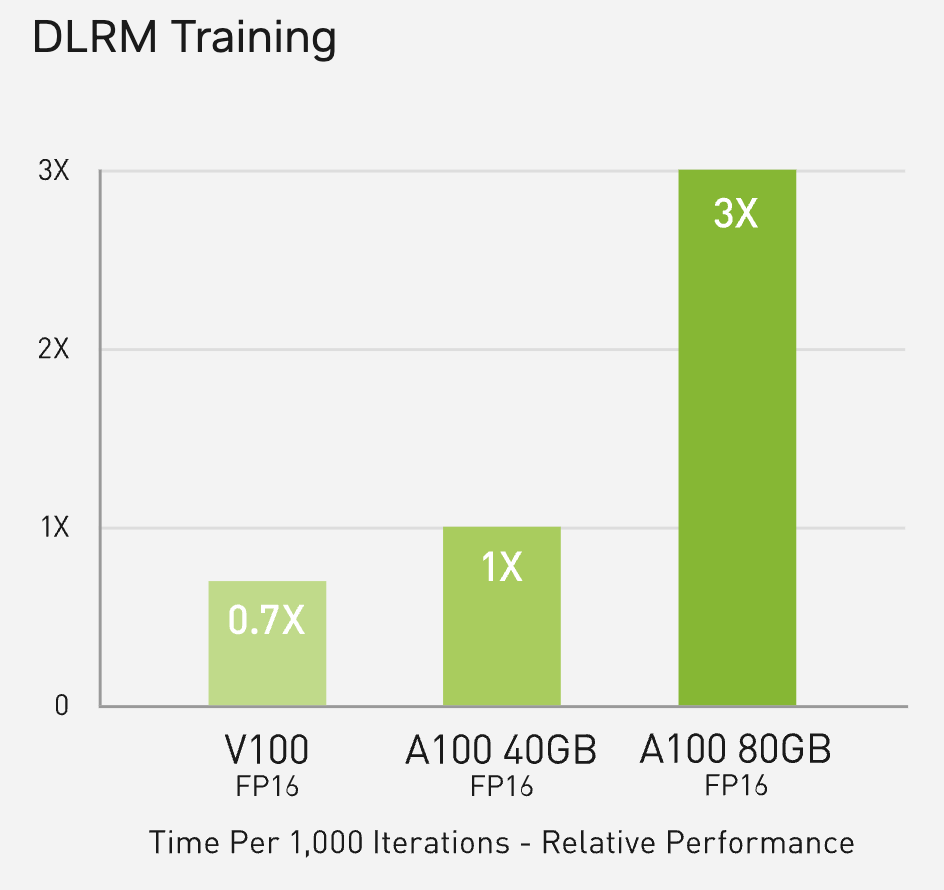
In a direct comparison, the A100 80GB is capable of 3x faster FP16 DLRM training than the A100 40GB (source: Nvidia.com)
Difference between the A100 PCIe and SXM
In addition to two memory configurations, it’s important to know that the A100 comes in two form factors, the SXM4 and PCIe.
Feature | A100 80GB PCIe | A100 80GB SXM |
|---|---|---|
Memory Bandwidth | 1,935 GB/s | 2,039 GB/s |
Max Thermal Design Power | 300W | 400W (up to 500W) |
Form Factor | PCIe | SXM |
Interconnect | NVLink Bridge for up to 2 GPUs: 600 GB/s | NVLink: 600 GB/s |
Multi-Instance GPU (MIG) | Up to 7 MIGs @ 5GB | Up to 7 MIGs @ 10GB |
The SXM version provides higher memory bandwidth and a higher maximum TDP, making it suitable for more intense workloads and larger server configurations. The PCIe version is more flexible in terms of cooling options and is designed for compatibility with a wider range of server setups.
A100 80GB vs 40GB Price Comparison
For a long time the NVIDIA A100 was in extremely limited supply, so you couldn’t buy access to its compute power even if you wanted. Today, availability has improved and you can access both the A100 40GB and 80GB on-demand or reserving longer term dedicated instances.
Current on-demand prices of A100 instances at DataCrunch:
80 GB A100 SXM4: 1.65/hour
40 GB A100 SXM4: 1.29/hour
*real time A100 prices can be found here.
Bottom line on the A100 40GB and 80GB
Both the A100 40GB and 80GB GPUs deliver exceptional performance for AI, data analytics, and HPC. The choice between the two models should be driven by the specific memory and bandwidth requirements of your workloads. The A100 80GB model, with its substantial increase in memory capacity and bandwidth, is the go-to option for the most demanding applications.
Now that you have a better idea of the difference between the 40GB and 80GB models of the A100, why not spin up an on-demand GPU instance with DataCrunch?