
Wenn du AI-Training oder -Inference auf NVIDIA-Hardware ausführst, bist du wahrscheinlich bereits mit CUDA vertraut. Was dir vielleicht weniger vertraut ist, ist die Hardwarebeschleunigung, die CUDA Cores den modernen High-End-GPUs von NVIDIA bringen.
In diesem Artikel werfen wir einen Blick darauf, wie CUDA Cores funktionieren, wie sie sich von Tensor Cores unterscheiden und wie sie deine AI-Projekte beschleunigen können.
Was sind CUDA Cores?
Ein CUDA Core ist eine kleine Verarbeitungseinheit in vielen NVIDIA-GPUs, die dafür ausgelegt ist, Rechenaufgaben parallel auszuführen.
Einfach ausgedrückt ist ein CUDA Core wie eine Mini-CPU, jedoch mit einem entscheidenden Unterschied: Während eine typische CPU nur über eine begrenzte Anzahl von Kernen verfügt, ist eine NVIDIA-GPU mit Tausenden einzelner CUDA Cores ausgestattet. Diese massive Parallelität ermöglicht es einer GPU, Tausende von Operationen gleichzeitig auszuführen, was sie besonders nützlich für Aufgaben macht, die in kleinere Teile aufgeteilt werden können – wie etwa Matrixoperationen.
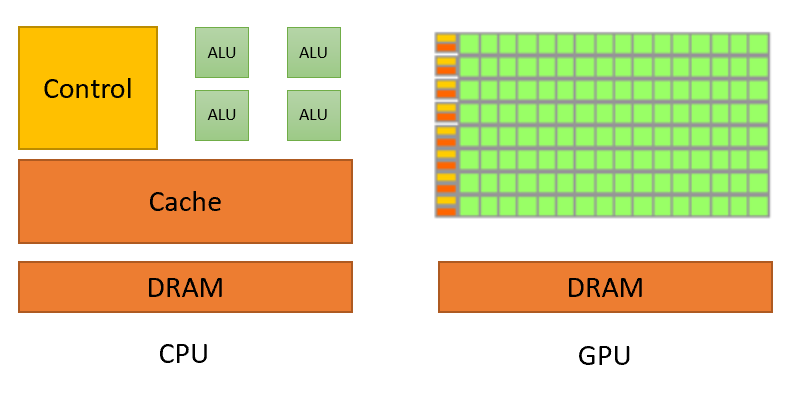
Visuelle Darstellung des Unterschieds zwischen CPUs und GPUs. Quelle: nvidia.com
Hintergrund im CUDA-Programmiermodell
NVIDIA führte CUDA (Compute Unified Device Architecture) im Jahr 2006 als Plattform und Programmiermodell ein, um allgemeine parallele Berechnungen auf seinen Hochleistungs-GPUs zu ermöglichen. CUDA Cores sind die Bausteine, die dies möglich machen, indem sie einer GPU erlauben, Berechnungen durchzuführen, die über das Rendern von Grafiken hinausgehen.
Wichtige Funktionsweisen von CUDA Cores
CUDA Cores basieren auf dem Prinzip der Parallelität. In AI und maschinellem Lernen ist diese Parallelität ein entscheidender Vorteil bei der Verarbeitung großer Datensätze. Während eine CPU möglicherweise nur ein oder zwei Aufgaben gleichzeitig erledigt, können die Tausenden von CUDA Cores einer GPU Hunderte oder Tausende von Aufgaben parallel ausführen und damit den Prozess erheblich beschleunigen.
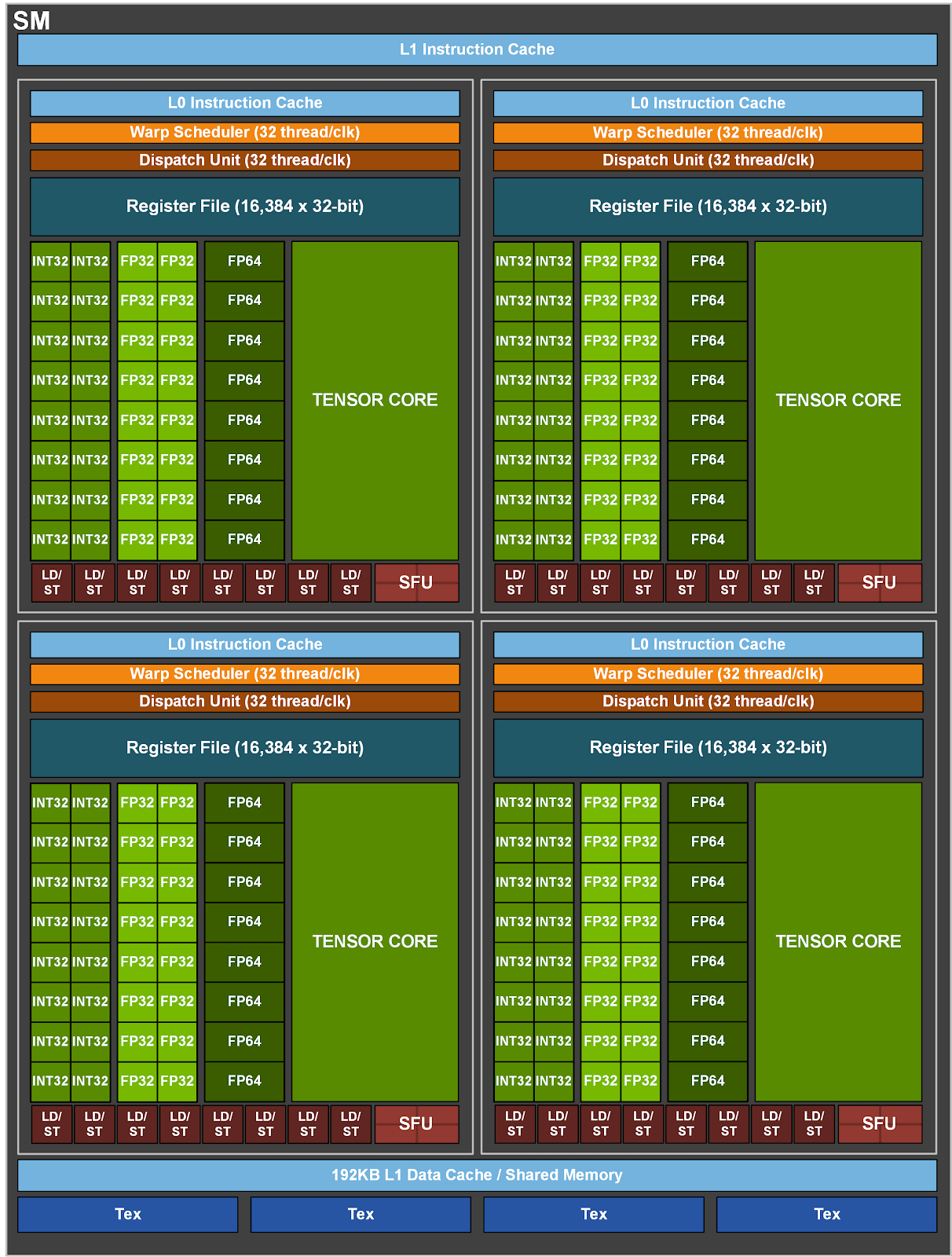
Illustration des A100 Streaming-Multiprozessors (SM), der 64 CUDA Cores enthält. Quelle: nvidia.com
Parallele Verarbeitung: Eine der wichtigsten Methoden, wie CUDA Cores Aufgaben beschleunigen, ist die parallele Verarbeitung. In einem Machine-Learning-Modell können Operationen wie Matrixmultiplikationen, Aktivierungen und Backpropagation parallel verarbeitet werden. CUDA Cores verteilen diese Operationen auf mehrere Threads und führen sie gleichzeitig aus. Dies ist besonders vorteilhaft, wenn mit großen Datensätzen oder Modellen gearbeitet wird, die umfangreiche Berechnungen erfordern.
Gleitkomma-Operationen: Machine-Learning-Modelle verlassen sich stark auf Gleitkomma-Arithmetik, insbesondere beim Berechnen von Gewichten und Biases in neuronalen Netzen. CUDA Cores sind darauf optimiert, Gleitkomma-Operationen mit enormer Geschwindigkeit zu verarbeiten. NVIDIA-GPUs mit CUDA Cores bieten eine hohe Durchsatzrate für Single-Precision (FP32 und Double-Precision (FP64) Gleitkomma-Operationen, die in Machine-Learning- und Data-Science-Workloads häufig vorkommen.
Workload-Verteilung: Ein weiterer wichtiger Aspekt der CUDA Core-Operation ist das Workload-Management. Beim Training eines neuronalen Netzes werden beispielsweise verschiedene Teile des Datensatzes parallel verarbeitet, wobei die CUDA Cores die Rechenlast über Tausende von Threads ausbalancieren. Diese Balance sorgt dafür, dass kein Kern ungenutzt bleibt, was zu einer schnelleren und effizienteren Verarbeitung führt.
Speicherzugriff und Effizienz: CUDA Cores spielen auch eine entscheidende Rolle dabei, wie eine GPU auf Speicher zugreift. Effizienter Speicherzugriff ist entscheidend, um eine hohe Leistung zu gewährleisten. CUDA Cores arbeiten in einer gut organisierten Speicherhierarchie, die globalen Speicher, Shared Memory und Registerspeicher umfasst. Der globale Speicher ist der größte, aber langsamste, während der Registerspeicher der schnellste, aber begrenzt ist. CUDA Cores und die Hardware-Architektur von NVIDIA verwalten den Datenfluss zwischen diesen Speicherarten, um die Effizienz zu maximieren. Dies ermöglicht eine schnellere Datenverarbeitung, die bei AI-Modellen, bei denen große Datensätze parallel geladen und verarbeitet werden, entscheidend ist.
Threading und Block-Management: NVIDIAs CUDA-Architektur organisiert Threads in
Blöcken und Gittern, um sicherzustellen, dass Aufgaben effektiv verwaltet werden. Wenn eine Berechnung erforderlich ist, führen die CUDA Cores die Threads gleichzeitig aus, und diese Threads werden in Blöcken gruppiert. Jeder Block wird weiter in Gittern organisiert, wodurch sichergestellt wird, dass die Arbeitslast gleichmäßig auf die CUDA Cores verteilt wird. Diese Architektur ermöglicht es, große Berechnungen, wie das Training eines Deep-Learning-Modells, in kleinere Aufgaben zu unterteilen und gleichzeitig zu verarbeiten. Das bedeutet, dass Aufgaben, die auf einer CPU Stunden oder Tage dauern würden, mit GPUs, die Tausende von CUDA Cores haben, in einem Bruchteil der Zeit abgeschlossen werden können.
Wie CUDA Cores mit Deep-Learning-Frameworks zusammenarbeiten
Die CUDA-Plattform wird auch von vielen der beliebten AI- und Machine-Learning-Frameworks wie TensorFlow und PyTorch unterstützt, was bedeutet, dass die meisten AI-Ingenieure von CUDA Cores profitieren, selbst wenn sie nicht explizit dafür programmieren. Diese hochrangige Integration abstrahiert einen Großteil der Komplexität, sodass die Benutzer sich darauf konzentrieren können, ihre Modelle zu erstellen, während die zugrunde liegende GPU die schweren Berechnungen beschleunigt.
CUDA Cores vs. Tensor Cores
Während CUDA Cores für allgemeine parallele Berechnungen wichtig sind, wurden Tensor Cores von NVIDIA im Jahr 2017 eingeführt, um speziell Deep-Learning-Aufgaben, insbesondere Matrixmultiplikationen, weiter zu beschleunigen. Tensor Cores tauchten erstmals in NVIDIAs Volta-Architektur auf (in GPUs wie der Tesla V100) und sind seitdem in GPUs basierend auf den Architekturen Turing, Ampere, Hopper und Blackwell enthalten.
Wichtige Unterschiede zwischen CUDA Cores und Tensor Cores
Es gibt auch einige klare Unterschiede in Bezug auf Anwendungsfälle, unterstützte Präzisionsstufen und AI-bezogene Leistung zwischen CUDA Cores und Tensor Cores, die du kennen solltest.
Allzweckberechnungen vs. spezialisierte Berechnungen:
CUDA Cores sind vielseitig und können eine breite Palette von Berechnungen durchführen, von einfachen Arithmetiken bis hin zu komplexen Algorithmen. Sie sind bei allgemeinen Aufgaben hervorragend geeignet und eignen sich für eine Vielzahl von Workloads.
Tensor Cores hingegen sind speziell für Deep-Learning-Aufgaben konzipiert und konzentrieren sich hauptsächlich darauf, Matrixoperationen zu beschleunigen. Diese Operationen sind grundlegend für die Forward- und Backward-Pass-Berechnungen beim Training neuronaler Netze, was Tensor Cores zu einem unschätzbaren Werkzeug für Deep-Learning-Anwendungen macht.
Präzisionsstufen:
CUDA Cores: Diese sind für Single-Precision (FP32) und Double-Precision (FP64) Gleitkomma-Operationen optimiert, die die am häufigsten verwendeten Präzisionsstufen in traditionellen Machine-Learning- und wissenschaftlichen Berechnungen sind.
Tensor Cores: Tensor Cores unterstützen im Gegensatz dazu Mixed-Precision-Berechnungen, insbesondere für Half-Precision (FP16)
und Integer (INT8) -Berechnungen. Dadurch können Modelle schneller trainiert werden und weniger Speicher beanspruchen, ohne dass die Genauigkeit wesentlich leidet.
Leistung bei AI und Deep Learning:
Tensor Cores bieten einen erheblichen Geschwindigkeitsvorteil, wenn es um Deep-Learning-Aufgaben wie das Training von Convolutional Neural Networks (CNNs) oder Transformers geht. Sie beschleunigen Matrixmultiplikationen und Akkumulationsoperationen, die im Zentrum dieser Modelle stehen.
CUDA Cores spielen zwar immer noch eine wichtige Rolle bei AI-Workloads, bieten aber nicht das gleiche Maß an Beschleunigung für Deep-Learning-Aufgaben. Sie übernehmen jedoch andere Aspekte der Workloads, wie Datenvorverarbeitung, Speicherverwaltung und nicht-matrixbezogene Operationen, was sie ebenfalls unverzichtbar für eine ausgewogene AI-Pipeline macht.
Die Anzahl der Tensor Cores und/oder CUDA Cores spielt eine Rolle bei der Geschwindigkeit, Effizienz und den Kosten deiner AI-Workloads. Dennoch ist es wahrscheinlicher, dass du die Leistung einer GPU als Ganzes betrachtest. Eine großartige Möglichkeit, Optionen zu vergleichen, ist MLPerf oder eine andere autoritative Benchmarking-Lösung.
Welche NVIDIA-GPUs nutzen CUDA Cores?
CUDA Cores sind in fast jeder modernen NVIDIA-GPU zu finden, von Consumer-Grafikkarten bis hin zu Enterprise-Lösungen, die für Rechenzentren entwickelt wurden. Werfen wir einen genaueren Blick auf die verschiedenen Arten von GPUs, die CUDA Cores nutzen:
Consumer-GPUs (GeForce-Serie):
Die GeForce-Serie von NVIDIA, wie die RTX 3080 oder RTX 4090, ist vor allem für ihre Gaming-Performance bekannt. Diese GPUs verfügen jedoch auch über eine beträchtliche Anzahl von CUDA Cores, was sie für AI-Forschung und Experimente geeignet macht. Entwickler und Hobbyisten nutzen diese GPUs oft, um Machine-Learning-Modelle zu prototypisieren, bevor sie auf leistungsstärkere Hardware umsteigen.
Professionelle GPUs (Quadro-Serie):
Die Quadro-Serie ist NVIDIAs Linie von professionellen GPUs, die für Aufgaben wie computergestütztes Design (CAD), Videobearbeitung und AI entwickelt wurden. Diese GPUs sind sowohl mit CUDA Cores als auch mit Tensor Cores ausgestattet, was sie ideal für AI-Ingenieure macht, die an anspruchsvolleren Workloads wie Modelltraining und komplexen Datensimulationen arbeiten.
Rechenzentrums-GPUs (Volta, Ampere, Hopper, Blackwell):
Diese GPUs werden häufig in Rechenzentren, Cloud-Umgebungen und Forschungseinrichtungen verwendet, um groß angelegte AI-Projekte zu bewältigen.
Unten findest du eine Übersicht über die Anzahl der Streaming-Multiprozessoren (SMs) und CUDA Cores verschiedener NVIDIA-GPUs.
GPU | Streaming Multiprocessors (SMs) | CUDA Cores |
|---|---|---|
144 | 18.432 | |
144 | 18.432 | |
132 | 16.896 | |
114 | 14.592 | |
142 | 18.176 | |
142 | 18.176 | |
84 | 10.752 | |
108 | 6.912 | |
80 | 5.120 |
Anmerkungen:
GH200 und H200: Diese GPUs nutzen die vollständige NVIDIA Hopper-Architektur mit allen 144 Streaming-Multiprozessoren (SMs). Jeder SM enthält 128 CUDA Cores, was zu insgesamt 18.432 CUDA Cores führt.
H100: Die H100-GPU ist in zwei Versionen erhältlich. Die SXM-Version verfügt über 132 SMs, von denen jeder 128 CUDA Cores enthält, was insgesamt 16.896 CUDA Cores ergibt. Die PCIe-Version hat weniger SMs und daher auch weniger CUDA Cores (14.592).
A100 (80GB und 40GB): Beide Speicher-Konfigurationen der A100 haben die gleiche Anzahl von CUDA Cores—6.912. Dies ergibt sich aus 108 SMs mit jeweils 64 CUDA Cores.
L40S und RTX 6000 Ada: Beide GPUs basieren auf der Ada-Lovelace-Architektur und verfügen über 142 SMs mit jeweils 128 CUDA Cores, was insgesamt 18.176 CUDA Cores ergibt.
A6000: Diese GPU basiert auf der Ampere-Architektur und hat 84 SMs mit jeweils 128 CUDA Cores, was insgesamt 10.752 CUDA Cores ergibt.
V100: Basierend auf der Volta-Architektur hat die V100 80 SMs mit jeweils 64 CUDA Cores, was zu insgesamt 5.120 CUDA Cores führt.
Wie viele CUDA Cores benötigst du für verschiedene Anwendungsfälle?
Die Anzahl der benötigten CUDA Cores variiert stark je nach Anwendungsfall. Grafisch intensive Videospiele und grundlegende Inhalte wie Videoschnitt erfordern in der Regel zwischen 1.500 und 10.000 CUDA Cores, während anspruchsvollere Aufgaben wie hochauflösende Videobearbeitung, High-Performance-Computing, Data Science und das Training von AI-Modellen von 5.000 bis 18.000 CUDA Cores profitieren.
Die Anzahl der CUDA Cores spiegelt die Fähigkeit einer GPU wider, parallele Berechnungen durchzuführen—mehr Cores verbessern in der Regel die Leistung für Aufgaben, die diese Parallelität nutzen können. Allerdings beeinflussen auch Faktoren wie die GPU-Architektur (neuere Architekturen bieten effizientere Cores), Speicherbandbreite, Speichergröße und Softwareoptimierung die Gesamtleistung erheblich. Spezialisierte Funktionen wie Tensor Cores und Multi-GPU-Verarbeitung beschleunigen zudem die Workloads beim AI-Training. Am Ende hängt die Effektivität einer GPU sowohl von den Hardwarefähigkeiten als auch der Softwareeffizienz ab—und nur auf die Anzahl der CUDA Cores zu achten, wird nicht weit führen.
Gibt es Alternativen zu CUDA Cores?
Während AMDs Stream-Prozessoren und Intels OneAPI alternative Plattformen für GPU-Computing bieten, können sie derzeit nicht mit der Leistung von NVIDIAs CUDA bei AI-Workloads mithalten.
CUDA hat sich als Industriestandard für GPU-beschleunigtes Rechnen in Deep Learning und Künstlicher Intelligenz etabliert und bietet ein ausgereiftes Ökosystem mit hoch optimierten Bibliotheken wie cuDNN und TensorRT, umfassenden Entwicklertools und starker Community-Unterstützung.
Im Gegensatz dazu entwickeln AMD und Intel ihre Software-Ökosysteme und Hardware-Integration für AI-Anwendungen noch weiter. Ihre Plattformen bieten nicht die gleiche Optimierung, umfassende Bibliotheken und weitverbreitete Akzeptanz, was sie weniger wettbewerbsfähig für AI-Workloads macht. Während sie in anderen Rechenbereichen tragfähige Optionen darstellen, sind sie derzeit weit davon entfernt, die Leistung und Effizienz von CUDA bei AI-Aufgaben zu erreichen.
Fazit zu CUDA Cores
CUDA Cores sind die stillen Helden der NVIDIA-GPUs, die eine unvergleichliche Parallelverarbeitung und Rechengeschwindigkeit ermöglichen und sie so unverzichtbar für AI- und Data-Science-Workloads machen. Von der Datenvorverarbeitung bis hin zum neuronalen Netzwerk-Training und der Inferenz beschleunigen CUDA Cores viele der ressourcenintensivsten Aufgaben, mit denen AI-Ingenieure konfrontiert sind.