
Mit so vielen Hochleistungs-GPUs, die NVIDIA in letzter Zeit auf den Markt gebracht hat, ist es schwierig, den Überblick über die einzigartigen Vorteile jedes Modells zu behalten.
Die NVIDIA L40S hat weniger Aufmerksamkeit erhalten als viele andere GPUs, aber sie hat eine einzigartige Position im Hochleistungsrechnen und spezifischen Deep-Learning-Anwendungsfällen gefunden.

Lassen Sie uns durchgehen, was Sie über die Spezifikationen und die Leistung der L40S im Vergleich zu zwei beliebteren Modellen, der A100 und der H100, wissen müssen.
Was ist die L40S?
Die L40S ist eine Anpassung von NVIDIAs Ada Lovelace GPU-Architektur. Sie können sie als eine aufgerüstete Version der L40 und einen entfernten Verwandten der RTX 4090 High-End-Gaming-Grafikkarte betrachten. Die L40 wurde ursprünglich für Grafik- und Simulations-Workloads in Rechenzentren entwickelt. Sie fand in Form der L40S ein neues Leben aufgrund der enormen Nachfrage nach GPUs für maschinelles Lernen und Inferenz.
Die L40S wurde im Oktober 2022 veröffentlicht und von NVIDIA als „die leistungsstärkste universelle GPU“ bezeichnet. Auf dem Papier ist sie in der Tat leistungsstark. Sie umfasst Tensor Core der 4. Generation, 142 RT-Kerne und 48 GB GDDR6-Speicher, der für Grafikleistung optimiert ist. Sie ist auch kompatibel mit NVIDIAs Transformer Engine-Technologie, die in der Hopper-Architektur zu finden ist.
Was ist der Unterschied zwischen der NVIDIA L40 und L40S?
Die NVIDIA L40 und L40S stammen aus derselben Architektur, doch die L40S stellt ein bedeutendes Upgrade dar, das speziell für KI- und Enterprise-Workloads optimiert wurde. Beide GPUs basieren auf der Ada-Lovelace-Architektur, doch die L40S bietet verbesserte Leistung, mehr Speicher und höhere Effizienz.Die wichtigsten Unterschiede sind:
Leistungssteigerung: Die L40S liefert höhere TFLOPs sowohl bei FP32- als auch bei gemischter Präzision, was sie besser für anspruchsvolle KI-Trainings- und Inferenzaufgaben geeignet macht.
Speichervorteil: Die L40S verfügt über mehr GPU-Speicher, wodurch sie größere Datensätze und komplexere KI-Modelle verarbeiten kann als die L40.
Zielanwendungen: Die L40 ist als vielseitige GPU für allgemeine Workloads wie Grafik- und leichtere KI-Anwendungen positioniert. Die L40S hingegen ist speziell für Hochleistungs-KI und Enterprise-Einsätze entwickelt worden.
Diese Verbesserungen machen die L40S zu einer überzeugenden Wahl für Nutzer, die in Cloud-Umgebungen maximale Leistung suchen. Sie bietet die perfekte Balance aus Leistung und Effizienz für anspruchsvolle KI-Workflows.
Die L40S wurde aufgrund der mangelnden Verfügbarkeit sowohl der A100 als auch der H100 populär. Diese beiden sind auch die besten Vergleiche in Bezug auf Spezifikationen und Leistung.
Vergleich der Spezifikationen von L40S, A100 und H100
GPU-Merkmale | NVIDIA A100 | NVIDIA L40S | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU-Architektur | Ampere | Ada Lovelace | Hopper |
GPU-Board-Formfaktor | SXM4 | Dual Slot PCIe | SXM5 |
GPU-Speicher | 40 oder 80 GB | 48 GB | 80 GB |
Speicherbandbreite | 1,6 bis 2 TB/s | 864 GB/s | 3,35 TB/s |
CUDA-Kerne | 6912 | 18176 | 14592 |
FP64 TFLOPS | 9,7 | N/A | 33,5 |
FP32 TFLOPS | 19,5 | 91,6 | 67 |
TF32 Tensor Core Flops* | 156 | 312 | 183 |
FP16 Tensor Core Flops* | 312 | 624 | 362 |
FP8 Tensor Core TFLOPS | N/A | 733 | 1446 |
Spitzen-INT8 TOPS* | 624 | 1248 | 733 |
L2-Cache | 40 MB | 96 MB | 50 MB |
Maximale thermische Verlustleistung (TDP) | 400 Watt | 350 Watt | 700 Watt |
*Ohne und mit strukturierter Sparsität
Auf der Suche nach weiteren Details zu Ihren Optionen? Erforschen Sie die Spezifikationen der A100 und H100 im Detail.
Leistungsvergleich
Es gibt klare Unterschiede in der Leistung zwischen der L40S, der A100 und der H100 bei FP64 (Doppelpräzision), FP32 (Einzelpräzision) und FP16 (Halbpräzision) Berechnungen.
FP64 (Doppelpräzision)
Die L40S unterstützt FP64 nativ nicht. In Anwendungen, die hohe Präzision erfordern, kann die L40S möglicherweise nicht so gut abschneiden wie die A100 und H100. Die H100, mit ihrer deutlich höheren FP64-Leistung, ist besonders gut für diese anspruchsvollen Aufgaben in der heutigen GPU-Landschaft geeignet.
FP32 (Einzelpräzision)
Bei der FP32 Tensor Core-Leistung übertrifft die L40S die A100 40GB erheblich und hat auf dem Papier auch eine gute Spitzenleistung im Vergleich zur H100. In speicherintensiven ML-bezogenen Fällen wird diese Leistung jedoch wahrscheinlich durch die geringere Speicherbandbreite der GPU im Vergleich sowohl zur A100 80GB als auch zur H100 ausgeglichen.
FP16 (Halbpräzision)
Die L40S, obwohl leistungsfähig, ist möglicherweise nicht die optimale Wahl für die anspruchsvollsten AI/ML-Workloads. Sie hat eine ähnliche Leistung wie die A100 40GB, wird jedoch deutlich von der A100 80GB und der H100 übertroffen.
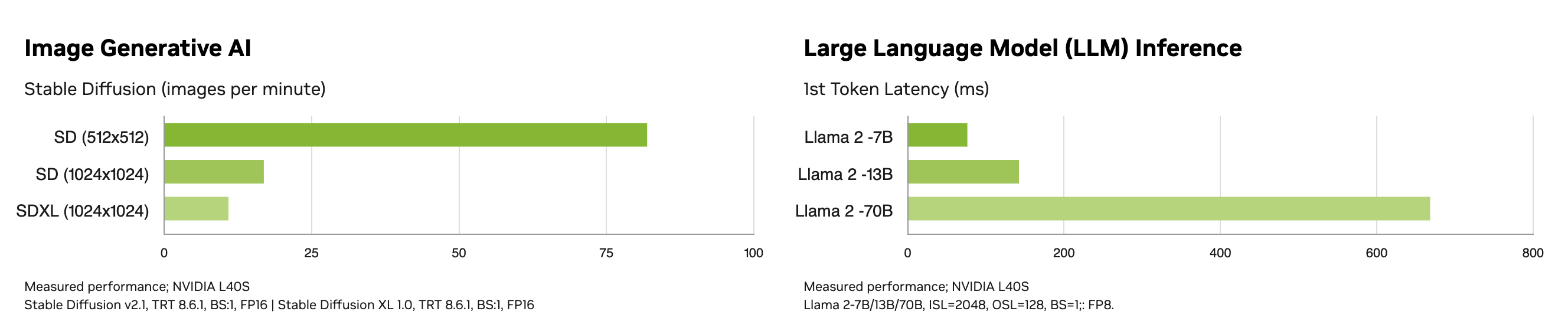
Niedrigere Speicherbandbreite in der L40S
Theoretische Spitzen-FLOPS geben kein vollständiges Bild. Für maschinelles Lernen spielt die Speicherbandbreite eine große Rolle beim Training und bei der Inferenz. Die L40S verwendet GDDR6 SGRAM-Speicher, eine gängige Art von Grafik-RAM, der für sein Gleichgewicht zwischen Kosten und Leistung bekannt ist. GDDR6 hat jedoch von Natur aus niedrigere Bandbreitenfähigkeiten im Vergleich zu HBM (High Bandwidth Memory)-Lösungen.
Die A100 und H100 hingegen nutzen HBM2e bzw. HBM3. Diese HBM-Technologien bieten aufgrund ihrer gestapelten Architektur und breiteren Dateninterfaces eine deutlich höhere Bandbreite. Dies ermöglicht eine viel schnellere Datenübertragungsrate zwischen der GPU und ihrem Speicher, was für Hochleistungsrechenaufgaben, bei denen große Datensätze beteiligt sind, entscheidend ist.
Der GDDR6-Speicher der L40S, während er für allgemeine Arbeitslasten geeignet ist, wird zu einem Engpass, wenn es darum geht, massive Datenübertragungen zu bewältigen, die für hochpräzise Berechnungen und komplexe AI/ML-Modelle erforderlich sind. Die HBM-Implementierungen in der A100 und H100 lösen dieses Problem und ermöglichen es ihnen, in diesen rechenintensiven Szenarien eine deutlich höhere Leistung zu erzielen.
Vergleich der Energieeffizienz
Die L40S hat eine maximale thermische Verlustleistung (TDP) von 350W, was niedriger ist als bei der A100 SXM4 (400W) und der H100 (700W). Während ein niedrigerer Stromverbrauch besser sein kann, ist dies bei Hochleistungsrechnen nicht der Fall. Es ist wichtig zu beachten, dass die L40S auch eine geringere Leistung im Vergleich zur A100 und H100 hat.
Die H100, obwohl sie die höchste TDP hat, bietet auch die höchste Leistung in allen Kategorien (FP16, FP32 und FP64). Infolgedessen hat die H100 eine bessere Leistung pro Watt als die A100 und L40S.
Preisvergleich der L40S mit A100 und H100
Während die Nachfrage nach Hochleistungs-GPUs hoch bleibt, verbessert sich die Verfügbarkeit der L40S auf Cloud-GPU-Plattformen wie DataCrunch. Hier ist, wie sie im Vergleich zu den Kosten pro Stunde mit der A100 und H100 abschneidet.
A100 40GB Kosten | L40S Kosten | A100 80GB Kosten | H100 SXM5 Kosten | |
|---|---|---|---|---|
On-Demand-Instanz | $1,29/Stunde | $1,10/Stunde | $1,75/Stunde | $2,65/Stunde |
↳ 2-Jahres-Preis | $0,97/Stunde | $1,83/Stunde | $1,31/Stunde | $1,99/Stunde |
8-GPU On-Demand-Instanz | $10,32/Stunde | $8,80/Stunde | $14,00/Stunde | $21,20/Stunde |
↳ 2-Jahres-Preis | $7,74/Stunde | $6,60/Stunde | $10,50/Stunde | $15,90/Stunde |
Wichtiger Punkt zu den Kosten: Der Preis pro Stunde der L40S ist vergleichbar mit der A100 40GB und deutlich niedriger als der der H100 bei einem 2-Jahres-Vertrag.
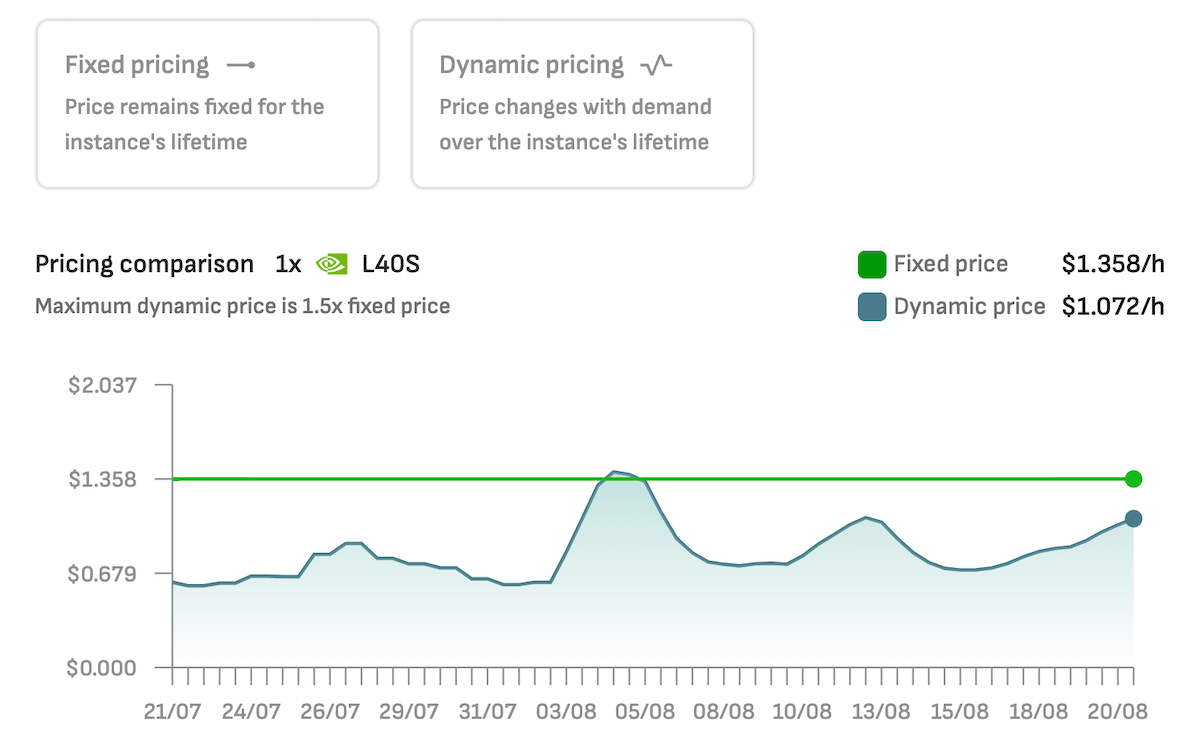
Mit DataCrunch können Sie auch die L40S mit dynamischer Preisgestaltung bereitstellen, bei der der Stundenpreis oft deutlich niedriger ist.
Fazit zur L40S
Sie können die NVIDIA L40S als einen Ausreißer im heutigen wettbewerbsintensiven Bereich der Computerbeschleuniger betrachten. Während sie nicht die rohe Leistungskapazität der H100 oder neuer Modelle hat, gibt es viele Bereiche, in denen sie sich günstig mit der A100 und früheren GPUs vergleichen lässt.
Stärken der L40S
Vielseitige Leistung: Die L40S zielt darauf ab, ein Gleichgewicht zwischen einer hohen Anzahl von CUDA-Kernen und RT-Kernen zu finden, was sie für ein breiteres Spektrum grafikintensiver Workloads geeignet macht.
Große Speicherkapazität: Ihre 48GB GDDR6-Speicher geben ihr einen kleinen numerischen Vorteil gegenüber der A100 40GB, sodass sie einige größere Modelle verarbeiten kann (jedoch mit einer geringeren Speicherbandbreite).
Einschränkungen der L40S
Rohe Rechenleistung: Für den absolut höchsten Trainingsdurchsatz bei massiven Modellen haben die A100 oder H100 aufgrund ihrer höheren rohen Rechenkapazitäten und der hohen HBM-Speicherbandbreite einen Vorteil.
Mangel an Präzision: Die L40S ist nicht in der Lage, FP64 zu verarbeiten, was bei Matrixberechnungen und dem Training vieler KI-Modelle ein Problem sein kann.
Auf dem heutigen Markt sollten Sie die L40S nicht außer Acht lassen. Sie können langfristig niedrigere Kosten und eine bessere Verfügbarkeit erwarten als bei der A100 80GB oder der H100. Sie ist eine vielseitige GPU für maschinelle Lernprojekte, bei denen die absolute Rechengeschwindigkeit nicht der wichtigste Entscheidungsfaktor ist.