
Als der Nvidia V100 im Jahr 2017 auf den Markt kam, stellte er den Höhepunkt der Hochleistungs-GPU-Technologie dar. Er spielte eine entscheidende Rolle bei der Entwicklung bahnbrechender KI-Modelle wie GPT-2 und GPT-3. Nicht zu vergessen, dass der V100 auch die Revolution im Design von Tensor Core-Chips einleitete.
Heute mag der V100 nicht mit der rohen Rechenleistung und Geschwindigkeit des A100 und H100 mithalten, aber er hat immer noch einen erheblichen Wert für spezifische Anwendungen. Lassen Sie uns einen aktuellen Leistungsvergleich und drei kreative Einsatzmöglichkeiten für den V100 in der heutigen GPU-Landschaft für KI-Training und -Inferenzen durchgehen.
NVIDIA V100 Tensor Core GPU
Der NVIDIA V100 war die erste GPU der Volta-Serie, die NVIDIA 2017 einführte. Zu dieser Zeit stellte er einen bedeutenden Sprung in der GPU-Technologie dar, indem Tensor Cores eingeführt wurden. Diese Kerne wurden speziell von NVIDIA entwickelt, um Matrixoperationen in Deep Learning- und KI-Workloads in einem rechenintensiven Rechenzentrum zu beschleunigen.
Trainingsgeschwindigkeit: Der V100 verzeichnete eine bis zu 12-fache Leistungssteigerung beim Deep Learning-Training im Vergleich zu Pascal-GPUs.
Speicher: Der V100 verfügt über 16 GB HBM2-Speicher mit einer Speicherbandbreite von bis zu 900 GB/s.
Leistung: Mit 640 Tensor Cores und 5.120 CUDA Cores liefert der V100 insgesamt 125 Teraflops Deep Learning (FP16)-Leistung.
Es besteht kein Zweifel, dass der V100 eine leistungsstarke und vielseitige GPU für KI-Projekte ist. Berühmt hat OpenAI über 10.000 V100s beim Training des GPT-3-Sprachmodells, das in ChatGPT verwendet wird, eingesetzt. Dennoch verblasst seine Leistung im Vergleich zu moderneren Hochleistungs-GPUs.
V100 vs A100 vs H100 Datenblattvergleich
GPU-Features | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU Board Form Factor | SXM2 | SXM4 | SXM5 |
Speicher | 16 GB | 40 oder 80 GB | 80 GB |
Speicherschnittstelle | 4096-bit HBM2 | 5120-bit HBM2 | 5120-bit HBM3 |
Speicherbandbreite | 900 GB/sec | 1555 GB/sec | 3000 GB/sec |
Transistoren | 21,1 Milliarden | 54,2 Milliarden | 80 Milliarden |
Maximaler thermischer Design Power (TDP) | 300 Watt | 400 Watt | 700 Watt |
Siehe detailliertere Vergleiche von V100 und A100 und A100 vs H100.
Allein anhand der technischen Spezifikationen sind der A100 und der H100 offensichtlich bessere Optionen für die meisten Deep Learning-Projekte. Der V100 bietet nicht die hohe Speicherbandbreite und den Speicher, die heute für die fortschrittlichsten KI-Modelle erforderlich sind. Wenn das Budget kein wesentlicher Engpass ist, sollten Sie wahrscheinlich leistungsfähigere Optionen sowohl für die Geschwindigkeit als auch für die Gesamtkosten des Eigentums wählen.
Drei kreative Einsatzmöglichkeiten für den V100
Während der A100 und H100 im Allgemeinen bessere Optionen sind, sprechen zwei Faktoren für den V100 – Kosten und Verfügbarkeit.
Kosten: Die Kosten pro Stunde des V100 auf Cloud-GPU-Plattformen wie DataCrunch sind im vergangenen Jahr deutlich gesunken. Einzelne GPU-Instanzen beginnen bei nur 0,39 $ pro Stunde.
Verfügbarkeit: Während A100s und H100s in begrenzterer Stückzahl verfügbar sind, können Sie relativ einfach und flexibel 8-GPU-Instanzen und sogar größere Cluster von V100s sichern.
Vor diesem Hintergrund sind hier drei kreative Anwendungsfälle, in denen der V100 eine glaubwürdige Option für Ihre KI-Trainings- oder Inferenzprojekte sein kann.
1. Multi-GPU-Koordination und Skalierung mit NVLINK
Eine der herausragenden Eigenschaften des V100 ist seine NVLINK-Fähigkeit, die es mehreren GPUs ermöglicht, direkt zu kommunizieren und die CPU zu umgehen, was zu erheblichen Geschwindigkeitsverbesserungen bei der Datenübertragung führt. Dies macht den V100 zu einer glaubwürdigen Wahl für die Einrichtung eines Testbeds für Multi-GPU-Systeme.
In einem aktuellen Beispiel experimentierten unsere KI-Ingenieure mit einem GPT-2-Modell mit 124 Millionen Parametern unter Verwendung der nativen Datenparallelität von PyTorch. Es war offensichtlich, dass, obwohl die Einrichtung etwa siebenmal langsamer war als eine 8x H100-Konfiguration, die erlernten Programmierpraktiken und Skalierbarkeitslektionen direkt übertragbar waren. Dies macht den V100 zu einer kosteneffektiven Plattform für Entwickler, um Multi-GPU-Anwendungen zu prototypisieren und zu verfeinern, bevor sie auf leistungsstärkere, aber auch teurere Systeme skalieren.
2. GPU-beschleunigte Datenwissenschaft mit RAPIDS
Ein weiterer potenzieller Anwendungsfall ist die Nutzung des V100 für kleine Datenwissenschaftsprojekte durch ein GPU-beschleunigtes Datenwissenschafts-Framework wie RAPIDS.
RAPIDS, entwickelt von NVIDIA, nutzt CUDA, um Datenwissenschafts-Workflows zu beschleunigen, indem Datenmanipulation und -berechnung direkt auf GPUs ermöglicht werden. Der Einsatz eines V100 kann die Datenvorverarbeitung, das Modelltraining und die Visualisierungsaufgaben innerhalb des RAPIDS-Frameworks erheblich beschleunigen und eignet sich ideal für kleine bis mittelgroße Datenwissenschaftsprojekte.
Die Kosteneffizienz des V100 im Vergleich zu leistungsstärkeren GPUs kann ihn zu einer glaubwürdigen Option für kleinere RAPIDS-Projekte machen.
3. Feinabstimmung kleinerer KI-Modelle
Der NVIDIA V100 bleibt auch eine gute Option zur Feinabstimmung älterer KI-Modelle wie GPT-2 aufgrund seiner ausreichenden Rechenleistung und Kosteneffizienz. Mit seinen 5.120 CUDA-Kernen und spezialisierten Tensor Cores kann der V100 viele Mixed-Precision-Training-Fälle bewältigen.
Darüber hinaus vereinfacht die Kompatibilität des V100 mit beliebten Deep Learning-Frameworks wie PyTorch und TensorFlow die Integration in bestehende Workflows. Dies macht ihn zu einer glaubwürdigen Wahl für Forscher und Entwickler, die ältere Modelle verfeinern und anpassen möchten, ohne teurere Hardware wie den A100 oder H100 zu benötigen.
Fazit zum V100 heute
Es ist zu früh, den V100 als veraltete Lösung abzutun. Während neuere Modelle wie der A100 und H100 eine überlegene Leistung bieten, stellt der Nvidia V100 immer noch eine überzeugende Option für bestimmte Szenarien aufgrund seiner Kosteneffizienz, seines Funktionsumfangs und seiner Kompatibilität mit älteren Systemen dar.
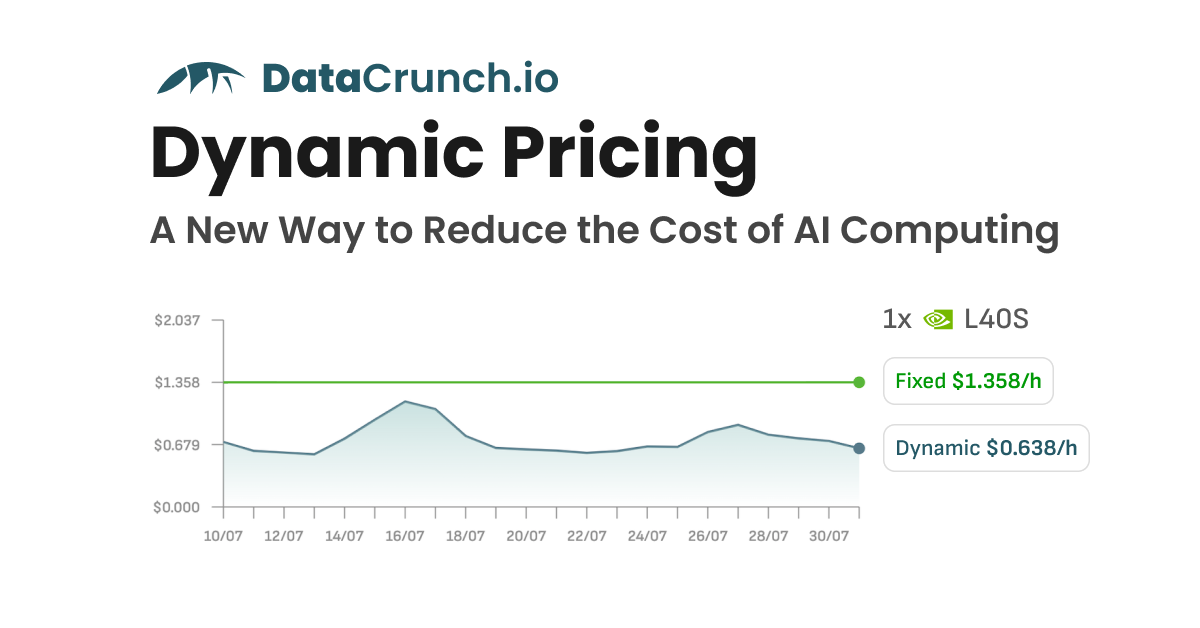
Sie können feste oder dynamische Preise für die Bereitstellung der NVIDIA V100 auf der DataCrunch Cloud-Plattform wählen.
NVIDIA V100 Preise bei DataCrunch
Die NVIDIA Tesla V100 16GB ist bei DataCrunch mit flexiblen Preisoptionen erhältlich, die auf Ihre Workload-Anforderungen zugeschnitten sind. Die V100 Preise variieren je nach Instanzgröße und Laufzeit:
On-Demand-Preise: Beginnen bei $0.39/Stunde für eine einzelne GPU-Instanz (1V100.6V) und reichen bis zu $3.12/Stunde für eine 8-GPU-Instanz (8V100.48V).
6-monatige Laufzeit: Rabatte senken die Preise leicht, mit der höchsten Instanz für $3.00/Stunde und der kleinsten für $0.37/Stunde.
2-jährige Laufzeit: Die größten Einsparungen gibt es bei einer zweijährigen Laufzeit, wobei die Preise auf bis zu $0.29/Stunde für eine einzelne GPU und $2.34/Stunde für die 8-GPU-Instanz sinken.
Alle Instanzen verfügen über NVLink (bis zu 50GB/s Bandbreite) für Multi-GPU-Konfigurationen und bieten eine Hochgeschwindigkeitskommunikation für anspruchsvolle Workloads. Ob Sie Single-GPU-Tests durchführen oder groß angelegte KI-Trainings ausführen, die flexiblen Pläne von DataCrunch bieten wettbewerbsfähige Preise für die V100 GPU.
Der V100 kann Aufgaben wie Multi-GPU-Experimente, GPU-beschleunigte Datenwissenschaft oder die Feinabstimmung kleinerer KI-Modelle bewältigen. Wenn Sie sehen möchten, wozu der V100 zu einem wettbewerbsfähigen Preis in der Lage ist, starten Sie heute eine Instanz auf DataCrunch.