
Wenn Sie ein KI-Ingenieur sind, sind Sie wahrscheinlich bereits mit der H100 basierend auf den von NVIDIA bereitgestellten Informationen vertraut. Lassen Sie uns einen Schritt weiter gehen und überprüfen, was die H100-GPU-Spezifikationen und der Preis für das maschinelle Lernen und die Inferenz bedeuten.
Eine völlig neue GPU-Architektur
Das "H" in H100 steht für die Hopper-Architektur, benannt nach der berühmten Informatikerin Grace Hopper. Dies ist eine völlig neue GPU-Architektur, die speziell mit einem starken Fokus auf die Beschleunigung cloudbasierter KI-Berechnungen entwickelt wurde.
Die Hopper-Architektur führt erhebliche Verbesserungen ein, einschließlich der 4. Generation von Tensor Cores, die für KI optimiert sind, insbesondere für Aufgaben, die Deep Learning und große Sprachmodelle umfassen.
H100 SXM vs. PCIe
Wie bei früheren hochleistungsfähigen GPUs von NVIDIA ist die H100 in zwei Hauptformfaktoren erhältlich, dem SXM5 und dem PCIe. Zwischen den beiden gibt es erhebliche Leistungsunterschiede.
H100 SXM5
Die SXM5-Konfiguration ist auf maximale Leistung und Multi-GPU-Skalierung ausgelegt. Sie verfügt über die höchste SM-Anzahl, eine schnellere Speicherbandbreite und eine überlegene Stromversorgung im Vergleich zur PCIe-Version. Der SXM5 ist ideal für anspruchsvolle KI-Trainings- und HPC-Workloads, die die höchstmögliche Leistung erfordern.
H100 PCIe Gen 5
Die PCIe Gen 5-Konfiguration ist eine eher mainstream Option, die eine Balance zwischen Leistung und Effizienz bietet. Sie hat eine geringere SM-Anzahl und reduzierte Leistungsanforderungen im Vergleich zur SXM5. Die PCIe-Version eignet sich für eine Vielzahl von Datenanalysen und allgemeinen GPU-Computing-Workloads.
H100-Datenblattvergleich von SXM vs. PCIe
Spezifikation | H100 SXM | H100 PCIe |
|---|---|---|
FP64 | 34 TFLOPS | 26 TFLOPS |
FP64 Tensor Core | 67 TFLOPS | 51 TFLOPS |
FP32 | 67 TFLOPS | 51 TFLOPS |
TF32 Tensor Core | 989 TFLOPS | 756 TFLOPS |
BFLOAT16 Tensor Core | 1.979 TFLOPS | 1.513 TFLOPS |
FP16 Tensor Core | 1.979 TFLOPS | 1.513 TFLOPS |
FP8 Tensor Core | 3.958 TFLOPS | 3.026 TFLOPS |
INT8 Tensor Core | 3.958 TOPS | 3.026 TOPS |
GPU-Speicher | 80GB | 80GB |
Speicherbandbreite der GPU | 3,35TB/s | 2TB/s |
Maximale thermische Verlustleistung (TDP) | Bis zu 700W | 300-350W |
Formfaktor | SXM | PCIe dual-slot |
Verbindung | NVLink: 900GB/s | NVLink: 600GB/s |
MLPerf-Benchmark-Leistung
Wir haben die Inferenzleistung von PCIe und SXM5 im MLPerf Machine Learning Benchmark evaluiert, mit Fokus auf zwei populäre Aufgaben:
LLM-Inferenz mit dem Llama 2 70B LoRA Modell und
Bildgenerierung mit Stable Diffusion XL.
Für beide Aufgaben verwendeten wir Konfigurationen mit 8 GPUs, jeweils ausgestattet mit 80 GB Speicher. veröffentlicht
Die Ergebnisse zeigen deutlich die Vorteile des SXM5-Formfaktors. SXM5 liefert eine beeindruckende 2,6-fache Beschleunigung bei der LLM-Inferenz im Vergleich zu PCIe. Bei der Bildgenerierung übertrifft der SXM5 PCIe immer noch um das 1,6-Fache, obwohl der Leistungsunterschied weniger ausgeprägt ist. Diese Ergebnisse unterstreichen den erheblichen Vorteil von SXM5 gegenüber PCIe, insbesondere bei großen, modernen Deep-Learning-Modellen.
Entwicklerwerkzeuge für H100
Wie zu erwarten, bietet NVIDIA eine vollständige Suite von Entwicklerwerkzeugen, um Anwendungen auf der H100 zu optimieren, zu debuggen und bereitzustellen. Diese Werkzeuge umfassen den NVIDIA Visual Profiler, NVIDIA Nsight Systems und NVIDIA Nsight Compute, die Entwicklern ermöglichen, die Leistung von Anwendungen zu analysieren und zu verbessern.
Darüber hinaus bietet die NVIDIA GPU Cloud (NGC) einen Katalog voroptimierter Softwarecontainer, Modelle und branchenspezifischer SDKs, die die Bereitstellung von KI- und HPC-Workloads auf H100-basierten Systemen vereinfachen.
CUDA-Plattform und Programmiermodell
Die H100 wird von der neuesten Version der CUDA-Plattform unterstützt, die verschiedene Verbesserungen und neue Funktionen enthält. Das aktualisierte Programmiermodell führt Thread Block Clusters ein, die eine effiziente Datenfreigabe und Kommunikation zwischen Thread-Blöcken ermöglichen und die Leistung bei bestimmten Arten von Workloads verbessern.
Frameworks, Bibliotheken und SDKs
NVIDIA bietet eine breite Palette von GPU-beschleunigten Bibliotheken, Frameworks und SDKs an, die für die H100 optimiert sind. Dazu gehören beliebte Deep-Learning-Frameworks wie TensorFlow und PyTorch sowie Hochleistungsbibliotheken wie cuDNN, cuBLAS und NCCL. Die H100 profitiert auch von domänenspezifischen SDKs wie NVIDIA Clara für das Gesundheitswesen und NVIDIA Morpheus für die Cybersicherheit.
H100-Einfluss auf MMA
Die NVIDIA H100 GPU führt mehrere Verbesserungen ein, die die Leistung von Matrix-Multiplikations- und Akkumulationsoperationen (MMA) erheblich verbessern:
Tensor Cores der vierten Generation: Die H100 verfügt über verbesserte Tensor Cores, die eine höhere Spitzenleistung für FP16, BF16 und die neuen FP8-Datentypen bieten im Vergleich zur vorherigen Generation der A100-GPU. Diese Tensor Cores sind für MMA-Operationen optimiert und ermöglichen eine schnellere Ausführung dieser kritischen mathematischen Funktionen in KI- und HPC-Workloads.
FP8-Präzision: Die H100 führt das neue FP8-Datenformat ein, das den vierfachen Durchsatz von FP16 auf der A100 bietet. Durch die Verwendung von FP8-Präzision für MMA-Operationen kann die H100 mehr Daten parallel verarbeiten, was zu einer höheren Gesamtleistung führt.
Transformer Engine: Die H100 enthält eine neue Transformer Engine, die sowohl Hardware als auch Software für transformerbasierte Modelle optimiert. Die Transformer Engine wählt dynamisch zwischen FP8- und FP16-Berechnungen und verwaltet das Umwandeln und Skalieren zwischen den beiden Formaten, um eine optimale Leistung für MMA-Operationen in diesen Modellen zu gewährleisten.
Diese architektonischen Verbesserungen der H100 GPU ermöglichen eine schnellere und effizientere Ausführung von MMA-Operationen, was zu erheblichen Leistungsgewinnen beim KI-Training, der Inferenz und bei HPC-Workloads führt, die stark auf diese mathematischen Funktionen angewiesen sind.
Vergleich der H100 mit der A100
Die H100 wird am natürlichsten mit der A100 verglichen, NVIDIAs vorheriger Hochleistungs-GPU. Zwischen den beiden gibt es viele klare Unterschiede.
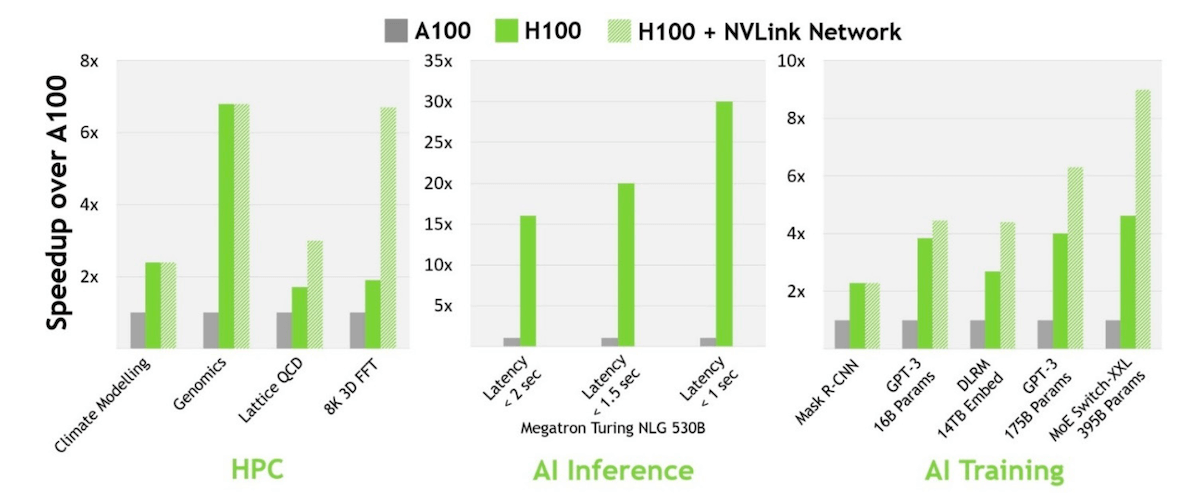
*Für weitere Details siehe H100 vs A100 Vergleich und H100 vs H200 Vergleich.
Verbesserungen des Streaming-Multiprozessors (SM): Die H100 verfügt über eine verbesserte SM-Architektur mit Tensor Cores der vierten Generation. Auf einer SM-Basis bieten die neuen Tensor Cores die doppelte Spitzenleistung für FP16- und BF16-Datentypen im Vergleich zur A100. Zusätzlich führt die H100 das neue FP8-Datenformat ein, das den vierfachen Durchsatz von FP16 auf der A100 bietet.
FP8 und Transformer Engine: Die Kombination aus FP8-Präzision und der Transformer Engine, die sowohl Hardware als auch Software für transformerbasierte Modelle optimiert, ermöglicht der H100, bis zu 9-fache höhere Leistung im Vergleich zur A100 beim KI-Training und 30-fach schnellere Inferenz-Workloads zu erreichen. Die Transformer Engine wählt dynamisch zwischen FP8- und FP16-Berechnungen und verwaltet das Umwandeln und Skalieren zwischen den beiden Formaten.
HBM3-Speichersubsystem: Die H100 ist die erste GPU, die über HBM3-Speicher verfügt und nahezu die doppelte Bandbreite des HBM2e-Speichers der A100 bietet. Mit 3 TB/s Speicherbandbreite kann die H100 effizient Daten an ihre Hochleistungs-Tensor-Cores und SMs liefern.
Multi-Instance GPU (MIG)-Verbesserungen: Die zweite Generation der MIG-Technologie in der H100 bietet etwa 3-fache Rechenkapazität und nahezu 2-fache Speicherbandbreite pro GPU-Instanz im Vergleich zur A100. Die H100 unterstützt bis zu sieben MIG-Instanzen, jede mit dedizierten NVDEC- und NVJPG-Einheiten, Leistungsmonitoren und Unterstützung für Confidential Computing.
*Für weitere Details siehe den Vergleich H100 vs A100.
Wie viel kostet die NVIDIA H100?
Die NVIDIA H100 ist eine Premium-Lösung, die Sie nicht einfach im Laden kaufen. Wenn H100s verfügbar sind, werden sie oft über dedizierte Cloud-GPU-Anbieter wie DataCrunch bereitgestellt.
Der Preis pro Stunde der H100 kann stark variieren, insbesondere zwischen den hochklassigen SXM5- und den allgemeineren PCIe-Formfaktoren. Hier sind die aktuell* besten verfügbaren Preise für die H100 SXM5:
Kosten für H100 SXM5 On-Demand:
$3,35/Stunde.
Kosten für H100 SXM5 mit 2-Jahres-Vertrag:
$2,38/Stunde.
Siehe Echtzeitpreis der A100 und H100.
Wenn Sie eine H100 bereitstellen, müssen Sie Ihren Bedarf an Rechenleistung und den Umfang Ihres Projekts abwägen. Für das Training größerer Modelle oder mit extrem großen Datensätzen sollten Sie möglicherweise ein Angebot für einen dedizierten H100-Cluster anfordern.
Fazit zur H100 GPU
Die NVIDIA H100 Tensor Core GPU, mit über 80 Milliarden Transistoren, ist einer der fortschrittlichsten Chips für intensive KI-Workloads.
Die H100 GPU ist in mehreren Konfigurationen erhältlich, einschließlich der Formfaktoren SXM5 und PCIe, sodass Sie die richtige Einrichtung für Ihre spezifischen Anforderungen auswählen können. Darüber hinaus können Sie eine Reihe neuer Softwarelösungen nutzen, die darauf abzielen, die immense Rechenkapazität der H100 optimal zu nutzen.
Da die Nachfrage nach beschleunigtem Rechnen weiter wächst, hat die NVIDIA H100 Tensor Core GPU bereits ihre Fähigkeit bewiesen, außergewöhnliche Leistung, Skalierbarkeit und Geschwindigkeit zu liefern. Dies bedeutet auch, dass die Verfügbarkeit der H100 auf dem allgemeinen Markt begrenzt ist. Wenn Sie die H100 für Ihre ML- oder Inferenzprojekte einsetzen möchten, ist Ihre beste Option, mit einem autorisierten NVIDIA-Partner wie DataCrunch zusammenzuarbeiten.