
Die Rolle von Tensor Cores im Parallelrechner
In den letzten Jahren haben wir massive Durchbrüche im Parallelrechner erlebt, dank Hardware- und Softwareinnovationen wie der Tensor-Core-Technologie von NVIDIA. Lassen Sie uns genauer betrachten, was Tensor Cores sind, wie sie funktionieren und wie sie sich von CUDA Cores unterscheiden.
Am Ende dieses Artikels werden wir auch erkunden, welche GPUs Tensor Cores besitzen und wie Sie diese für Ihre KI-Projekte nutzen können – insbesondere in skalierbaren Cloud-Umgebungen.
Hardware-Beschleunigung durch GPUs
Wir alle wissen, dass KI-Workloads, insbesondere Aufgaben im Bereich des Deep Learnings, enorme Mengen an Matrixmultiplikationen erfordern. Die Skalierung der für das Training von Transformermodellen mit Billionen von Parametern erforderlichen Berechnungen wäre ohne Hardwarebeschleunigung und Parallel Computing nicht möglich.
Während eine herkömmliche CPU (Central Processing Unit) diese Aufgaben bewältigen kann, wird die schiere Menge an Berechnungen schnell überwältigend. Hier kommen Grafikprozessoren (GPUs) ins Spiel. GPUs sind für Parallelität ausgelegt und damit viel schneller als CPUs bei rechenintensiven Matrixoperationen. Doch selbst innerhalb von GPUs gibt es Raum für spezialisierte Hardwarebeschleunigung im Bereich des Parallel Computing, und genau hier kommen Tensor Cores ins Spiel.
Was sind Tensor Cores?
Tensor Cores sind spezialisierte Verarbeitungseinheiten, die in bestimmten NVIDIA-GPUs wie der A100, H100 und H200 zu finden sind. Sie wurden entwickelt, um Deep-Learning-Aufgaben, insbesondere Matrixoperationen, zu beschleunigen.
Der Name "Tensor" leitet sich von dem mathematischen Objekt "Tensor" ab, das Skalare, Vektoren und Matrizen verallgemeinert. Tensor-Berechnungen sind in KI-Modellen von grundlegender Bedeutung, da neuronale Netze Gewichte und Aktivierungen als mehrdimensionale Arrays (oder Tensoren) darstellen.

Konzeptionelle Darstellung der Tensor Cores in KI-Berechnungen für Transformer-Modelle. Quelle: nvidia.com
Was macht Tensor Cores einzigartig?
Ein wesentliches Merkmal der Tensor Cores ist ihre Fähigkeit, Matrixmultiplikationen mit gemischter Genauigkeit (Mixed-Precision-Arithmetik) durchzuführen. Das bedeutet, dass Tensor Cores Matrixmultiplikationen schneller berechnen können, indem sie Halbpräzisions-Gleitkommazahlen (FP16) und Gleitkommazahlen mit einfacher Genauigkeit (FP32) kombinieren. Dieser Ansatz bietet eine erhebliche Geschwindigkeitssteigerung, ohne viel an Genauigkeit zu verlieren.
Tensor Cores sind so konzipiert, dass sie Matrixmultiplikationen auf eine äußerst effiziente Weise beschleunigen. Durch ihre spezialisierte Bauweise können sie enorme Datenmengen in einem Bruchteil der Zeit verarbeiten, die selbst für leistungsstarke traditionelle GPU-Kerne, wie CUDA Cores, erforderlich wäre.
Tensor Cores sind ein wesentlicher Bestandteil, um die heutigen neuronalen Netzwerke effizienter zu gestalten. Sie ermöglichen es uns, Transformer-Modelle mit Billionen von Parametern zu trainieren und KI-Systeme in großem Maßstab einzusetzen.
Was sind die Vorteile von Tensor Cores?
Der wesentliche Vorteil der Tensor Cores besteht darin, dass sie mehrere Operationen parallel ausführen und die riesigen Datenmengen bewältigen, die das Deep Learning erfordert. In der Praxis verkürzen Tensor Cores die Trainingszeit von Modellen erheblich, was es ermöglicht, in kürzerer Zeit mehr Iterationen durchzuführen. Diese Geschwindigkeitssteigerung kann sich auch in Kosteneinsparungen niederschlagen, insbesondere in Cloud-Umgebungen wie der DataCrunch Cloud Platform, wo Sie stundenweise bezahlen können.

Illustration: H100 bietet bis zu 6-fache Rechenleistung für KI-Aufgaben im Vergleich zur A100 dank der 4. Generation der Tensor Cores. Quelle: nvidia.com
Wie funktionieren Tensor Cores?
Tensor Cores sind so konzipiert, dass sie in einem einzigen Taktzyklus Operationen auf 4x4-Matrixtiles durchführen und dabei Eingaben mit gemischter Genauigkeit verarbeiten.
Wenn Sie beispielsweise ein Deep-Learning-Modell haben, das mit FP32-Genauigkeit arbeitet, können Tensor Cores bestimmte Teile der Berechnung mit FP16 durchführen, wodurch der Prozess beschleunigt wird, ohne die Genauigkeit der Ergebnisse signifikant zu beeinträchtigen. Dies ist besonders nützlich bei der Verarbeitung sehr großer Datensätze, da die Geschwindigkeitssteigerung die Trainingszeit drastisch reduzieren kann.
Tensor Cores vs CUDA Cores
Obwohl sowohl Tensor Cores als auch CUDA Cores wesentliche Bestandteile moderner, auf KI ausgerichteter NVIDIA-GPUs sind, haben sie unterschiedliche Aufgaben.
CUDA Cores sind universelle Kerne, die eine breite Palette an Parallelrechenaufgaben bewältigen können, von 3D-Rendering bis hin zu wissenschaftlichen Simulationen. Im Gegensatz dazu sind Tensor Cores spezialisierte Hardware, die speziell für KI-Workloads entwickelt wurde.
Der Hauptvorteil der Tensor Cores gegenüber den CUDA Cores liegt in ihrer Fähigkeit, Matrixoperationen mit gemischter Genauigkeit (Mixed-Precision) mit deutlich höherem Durchsatz durchzuführen. Tensor Cores beschleunigen Matrixmultiplikationen und Faltungsoperationen, zwei Schlüsselprozesse in Deep-Learning-Modellen. Während CUDA Cores diese Operationen ebenfalls ausführen können, geschieht dies mit Standardpräzision und dauert bei großen Matrizen in der Regel länger.
Vorteil der gemischten Präzision bei Tensor Cores
Im Mixed-Precision-Modus können Tensor Cores FP16 (Halbpräzisions-Gleitkomma) und FP32 (Einzelpräzisions-Gleitkomma) kombinieren, was eine Balance zwischen Leistung und Genauigkeit ermöglicht. Die Verwendung von FP16 erlaubt schnellere Berechnungen und verringert die Speicherbandbreite, während FP32 sicherstellt, dass kritische Teile der Berechnung eine höhere Genauigkeit beibehalten. Diese Kombination beschleunigt das Training erheblich und ermöglicht schnellere Iterationen bei großen Modellen.
Zusammengefasst:
CUDA Cores: Vielseitige, universelle Prozessoren für parallele Aufgaben.
Tensor Cores: Spezialisierte Hardware für Deep Learning, insbesondere für rechenintensive Matrixberechnungen wie das Training von neuronalen Netzen. Sie sind schneller bei KI-Aufgaben und optimiert für gemischte Präzisionsarithmetik.
GPUs mit Tensor Cores
NVIDIA hat Tensor Cores mit der Volta-Architektur eingeführt, beginnend mit der V100-GPU, die speziell für Rechenzentren und KI-Forschung entwickelt wurde. Seitdem sind Tensor Cores ein Standardmerkmal in mehreren NVIDIA-GPU-Familien geworden, die jeweils die Leistung verbessern und KI-Workloads effizienter machen.
Hier eine Übersicht der wichtigsten GPU-Architekturen mit Tensor Cores:
Architektur | GPU-Beispiele | Generation der Tensor Cores |
|---|---|---|
Volta | 1. Generation | |
Turing | RTX 20 Serie | 2. Generation |
Ampere | 3. Generation | |
Ada Lovelace | 4. Generation | |
Hopper | 4. Generation | |
Blackwell | 5. Generation |
Jede Generation der Tensor Cores hat den Durchsatz und die Effizienz von Deep-Learning-Workloads verbessert und sie schneller sowie energieeffizienter gemacht. Abhängig von Ihrem KI-Projekt, Budget und Leistungsanforderungen können Sie aus einer Reihe von GPUs wählen, die Tensor Cores für Trainings- und Inferenzaufgaben nutzen.
Wie Tensor Cores KI-Projekte beeinflussen
Tensor Cores verändern die Spielregeln, wenn es um das Training und die Inferenz von KI-Modellen geht. Für Data Scientists ist der bemerkenswerteste Effekt die Verkürzung der Trainingszeit. Große KI-Modelle können auf traditioneller Hardware Wochen oder sogar Monate zum Training benötigen, aber mit Tensor Cores wird dieser Prozess um ein Vielfaches beschleunigt.
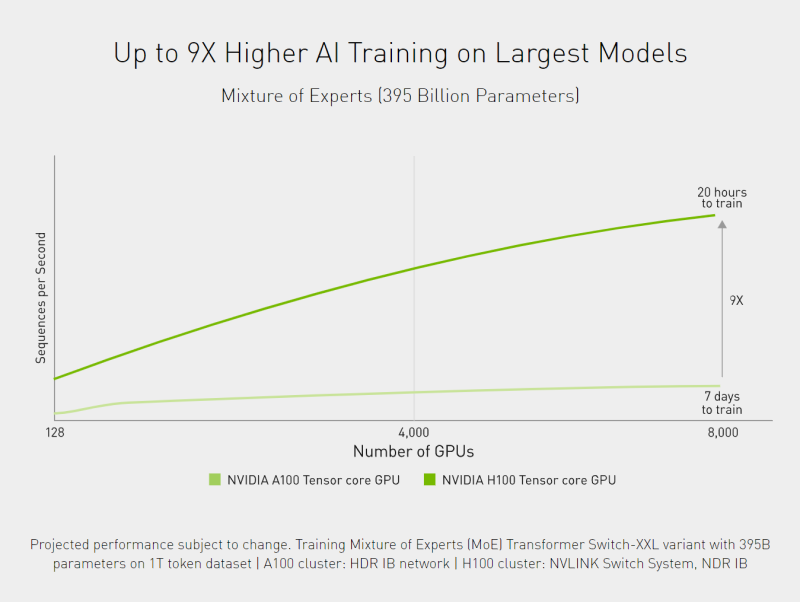
Beispiel für bis zu 9x schnellere Trainingszeiten dank der Tensor-Core-Technologie. Quelle: nvidia.com
Neben der Verkürzung der Trainingszeiten verbessern Tensor Cores auch die Inferenzleistung. Bei der Bereitstellung von KI-Modellen in der Produktion ist die Geschwindigkeit, mit der Vorhersagen getroffen werden, entscheidend, insbesondere bei Echtzeitanwendungen wie Empfehlungssystemen, autonomen Fahrzeugen oder Spracherkennungssystemen. Tensor Cores sorgen dafür, dass diese Vorhersagen mit geringer Latenz erfolgen, was für KI-Anwendungen, die Echtzeitergebnisse erfordern, unerlässlich ist.
Cloud-GPUs und Tensor Cores
Wenn Sie planen, ein neues Transformer-Modell zu trainieren, kombinieren sich die Vorteile der Tensor Cores hervorragend mit der Möglichkeit, Cloud-GPUs bei Bedarf zu nutzen. Über Cloud-GPU-Anbieter wie DataCrunch können Sie auf leistungsstarke Parallelrechner zugreifen, ohne große Kapitalinvestitionen in Hardware tätigen zu müssen.
Ein großer Vorteil der Nutzung von Cloud-basierten Tensor-Core-GPUs ist die Möglichkeit, den Ressourceneinsatz an die Projektanforderungen anzupassen. Wenn Sie ein Modell haben, das intensive Trainingsressourcen benötigt, aber nur für kurze Zeit, kann das Mieten von Cloud-GPU-Instanzen mit Tensor Cores eine kostengünstigere Lösung sein als der Kauf von physischer Hardware.
Der Schlüssel zur Kosteneffizienz liegt im effizienten Ressourcenmanagement:
Wählen Sie die richtige GPU:
Verschiedene KI-Workloads profitieren von unterschiedlichen GPUs. Wenn Ihr Workload beispielsweise sehr große Modelle umfasst, könnte eine NVIDIA H100-Instanz (mit Tensor Cores der vierten Generation) ideal sein, da sie in der Lage ist, massive Datensätze und Modelle zu verarbeiten. Andererseits könnte die V100 für kleinere Modelle ausreichen und dabei geringere Kosten pro Stunde verursachen.
Nutzen Sie dynamische Preisinstanzen:
Für nicht dringende Aufgaben wie das Training kleinerer Modelle können Sie mit
erhebliche Kosteneinsparungen erzielen.
Nutzen Sie das Mixed-Precision-Training:
Verwenden Sie wann immer möglich den Mixed-Precision-Support für Tensor-Core-fähige Instanzen. Dies kann die Leistung optimieren, indem FP16-Präzision dort genutzt wird, wo es möglich ist, und FP32 dort, wo es nötig ist, wodurch die Geschwindigkeit verbessert wird, ohne die Genauigkeit des Modells zu beeinträchtigen.
NVIDIA-Bibliotheken und -Tools zur Unterstützung von Tensor Cores
NVIDIA stellt mehrere Bibliotheken bereit, die die Nutzung von Tensor Cores erleichtern. Diese Bibliotheken sind für Deep-Learning-Workloads optimiert und stellen sicher, dass Tensor Cores effizient genutzt werden:
cuBLAS und cuDNN: NVIDIAs cuBLAS (Basic Linear Algebra Subprograms) und cuDNN (Deep Neural Network)-Bibliotheken sind hochoptimiert für KI-Workloads. Sie kümmern sich um niedrigstufige Matrixoperationen und sorgen dafür, dass Tensor Cores bei Aufgaben wie Faltungsoperationen und Matrixmultiplikationen zum Einsatz kommen.
TensorRT: TensorRT ist ein von NVIDIA entwickeltes Toolkit zur Optimierung der Inferenz, das darauf ausgelegt ist, Tensor Cores bei der Bereitstellung von KI-Modellen für die Inferenz zu nutzen. TensorRT hilft dabei, trainierte Modelle zu optimieren, indem es den Speicherbedarf und die Latenz reduziert, was besonders für Echtzeitanwendungen nützlich ist.
Durch die Nutzung dieser Tools können Sie sicherstellen, dass Ihre KI-Modelle effizient auf Tensor-Core-GPUs ausgeführt werden, was die Trainings- und Inferenzzeiten reduziert.
Anpassung der Modellarchitektur
Eine weitere Möglichkeit, die Nutzung von Tensor Cores zu optimieren, besteht darin, die Modellarchitektur anzupassen. Wenn Sie mit Tensor Cores arbeiten, können größere Batch-Größen zu einer erheblichen Leistungssteigerung führen. Dies liegt daran, dass Tensor Cores Operationen parallel verarbeiten, und größere Batches es ihnen ermöglichen, ihre Durchsatzleistung zu maximieren. Das Experimentieren mit größeren Batch-Größen hängt jedoch von den Speicherkapazitäten Ihrer Hardware und der spezifischen Natur Ihres Modells ab.
Herausforderungen und Überlegungen
Obwohl Tensor Cores erhebliche Vorteile für KI-Workloads bieten, gibt es einige Herausforderungen und Überlegungen:
Nicht alle Modelle profitieren gleichermaßen:
Tensor Cores sind am effektivsten bei großflächigen Matrixoperationen, die im Deep Learning üblich sind. Bei nicht auf Deep Learning ausgerichteten Aufgaben oder Modellen mit kleineren Matrizen bieten Tensor Cores möglicherweise keinen spürbaren Leistungsanstieg gegenüber CUDA Cores.
Framework-Kompatibilität: Um von Tensor Cores vollständig zu profitieren, muss Ihr Deep-Learning-Framework das Mixed-Precision-Training unterstützen. Während große Frameworks wie TensorFlow und PyTorch ausgezeichnete Unterstützung bieten, sind ältere oder weniger verbreitete Frameworks möglicherweise nicht für die Nutzung von Tensor Cores optimiert.
GPU-Speicher: Mixed-Precision-Training reduziert den Speicherbedarf, aber große Modelle oder Batch-Größen können dennoch den Speicher der GPU überlasten. Sie müssen Batch-Größen und Speichernutzung sorgfältig verwalten, um Speicherengpässe zu vermeiden.
Fazit zu Tensor Cores
Tensor Cores sind ein zentraler Bestandteil der effizienten Parallelverarbeitung und besonders hilfreich bei groß angelegten Deep-Learning-Aufgaben. Sie beschleunigen Matrixoperationen und verbessern sowohl die Trainings- als auch die Inferenzzeiten, was es ermöglicht, effizienter mit größeren Modellen und Datensätzen zu arbeiten. Die Kombination von Mixed-Precision-Training, NVIDIAs Software-Ökosystem und Cloud-Plattformen wie DataCrunch bietet unvergleichliche Flexibilität und Skalierbarkeit.
Wenn Sie Fragen dazu haben, wie Sie Tensor Cores in Ihren Deep-Learning-Projekten einsetzen können, kontaktieren Sie unsere KI-Ingenieure für eine Beratung.