
Es fühlt sich an, als wäre es schon lange her, dass NVIDIA im November 2023 die H200-GPU vorgestellt hat. Seitdem haben wir bereits von AMDs MI300X und der kommenden Blackwell-Architektur erfahren. Ganz zu schweigen davon, dass der NVIDIA-Aktienkurs durch die Decke gegangen ist!
Schauen wir uns an, was die H200 zu bieten hat – und vor allem, was die massive Steigerung des VRAMs und der Speicherbandbreite für Anwendungsfälle im maschinellen Lernen, insbesondere beim Training und bei der Inferenz, bedeutet.
Was ist die NVIDIA H200?
Die NVIDIA H200 ist eine Tensor Core GPU, die speziell für den Einsatz im Hochleistungsrechnen und für KI-Anwendungsfälle entwickelt wurde. Sie basiert auf der Hopper-Architektur, die selbst in der zweiten Hälfte des Jahres 2022 veröffentlicht wurde.
Die H200 baut auf dem Erfolg von NVIDIAs vorheriger Flaggschiff-GPU, der H100, auf, indem sie bedeutende Fortschritte in den Bereichen Speicherkapazität, Bandbreite und Energieverbrauchsleistung einführt. Diese Verbesserungen positionieren die H200 als marktführende GPU für generative KI, große Sprachmodelle und speicherintensive HPC-Anwendungen.
Vollständiger Vergleich der H200- und H100-Spezifikationen
Technische Spezifikationen | H100 SXM | H200 SXM |
Formfaktor | SXM5 | SXM5 |
FP64 | 34 TFLOPS | 34 TFLOPS |
FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
FP32 | 67 TFLOPS | 67 TFLOPS |
TF32 Tensor Core* | 989 TFLOPS | 989 TFLOPS |
BFLOAT16 Tensor Core* | 1,979 TFLOPS | 1,979 TFLOPS |
FP16 Tensor Core* | 1,979 TFLOPS | 1,979 TFLOPS |
FP8 Tensor Core* | 3,958 TFLOPS | 3,958 TFLOPS |
INT8 Tensor Core* | 3,958 TFLOPS | 3,958 TFLOPS |
GPU-Speicher | 80 GB | 141 GB |
Speicherbandbreite | 3,35 TB/s | 4,8 TB/s |
Maximale thermische Verlustleistung (TDP) | Bis zu 700W (konfigurierbar) | Bis zu 700W (konfigurierbar) |
Multi-Instance GPUs | Bis zu 7 MIGs @10GB je | Bis zu 7 MIGs @16.5GB je |
Verbindung | NVIDIA NVLink®: 900GB/s PCIe Gen5: 128GB/s | NVIDIA NVLink®: 900GB/s PCIe Gen5: 128GB/s |
*Mit Sparsität
Insgesamt wird erwartet, dass die H200 eine aufgerüstete Version der H100-Spezifikationen ist und eine ähnliche Bandbreite an Rechenkapazitäten (FP64 bis INT8) beibehält, jedoch durch die VRAM-Upgrades eine schnellere und effizientere Leistung bietet. Während die H200 eine solide Option sein wird, wird die neue GB200 NVL72 in den kommenden Jahren die führende GPU für Rechenzentren von NVIDIA sein.
Speicher- und Bandbreiten-Upgrade
Im Herzen der Leistung der H200 steht ihr 141 GB großer HBM3e-Speicher (High-Bandwidth Memory), der mit einer Speicherbandbreite von 4,8 TB/s geliefert wird. Im Vergleich dazu verfügte die vorherige Generation, die H100 GPU, über 80 GB HBM3-Speicher mit respektablen 3,3 TB/s Bandbreite.
Aktualisierte Benchmark-Leistung
Aktuelle Benchmarks zeigen die beeindruckenden Fähigkeiten der H200:
Llama2-13B Modell-Inferenz: Die H200 erreicht etwa 11.819 Tokens pro Sekunde beim Llama2-13B-Modell, was eine 1,9-fache Leistungssteigerung im Vergleich zur H100 darstellt.
Llama2-70B Modell-Inferenz: Beim Llama2-70B-Modell liefert die H200 bis zu 3.014 Tokens pro Sekunde und zeigt damit ihre Effizienz bei der Verarbeitung größerer Modelle.
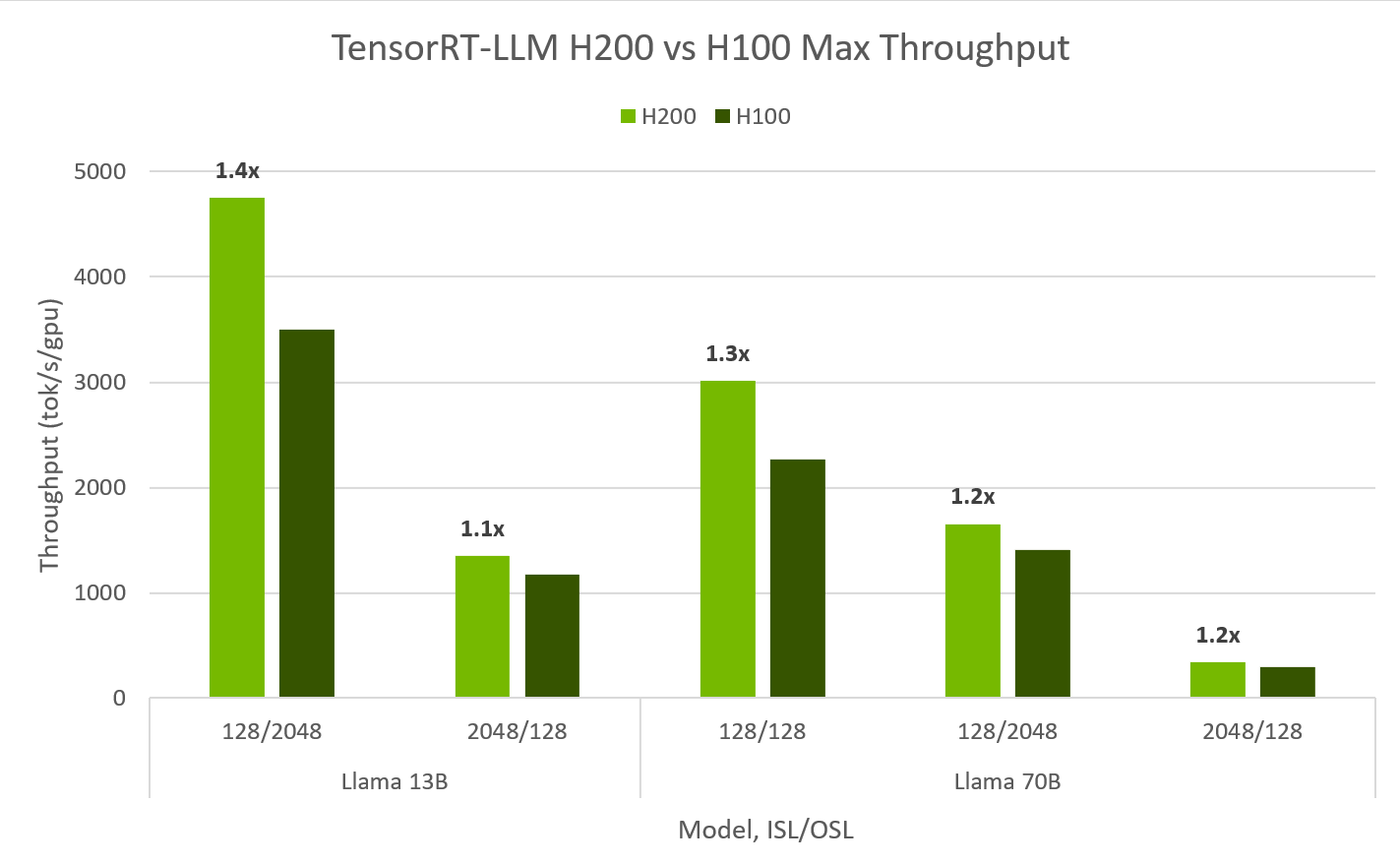
Diese Benchmarks unterstreichen die verbesserte Speicherkapazität und Bandbreite der H200, die eine schnellere und effizientere Inferenz für große Sprachmodelle ermöglicht.
Über die LLM-Inferenz hinaus liefert die H200 auch beeindruckende Leistungssteigerungen in anderen AI-Bereichen, wie generative AI und Trainingsdurchsatz. Beim neuen Test für Graph Neural Networks (GNN) basierend auf R-GAT erzielte die H200 eine 47%ige Steigerung beim GNN-Training auf einem einzelnen Knoten im Vergleich zur H100.
Auswirkungen auf die thermische Verlustleistung (TDP)
Die H200 erzielt Leistungsverbesserungen, während sie das gleiche Leistungsprofil wie die H100 beibehält. Obwohl dies nicht wie ein Upgrade klingt, wird die erwartete Leistung pro Watt für Rechenleistung erheblich besser sein.
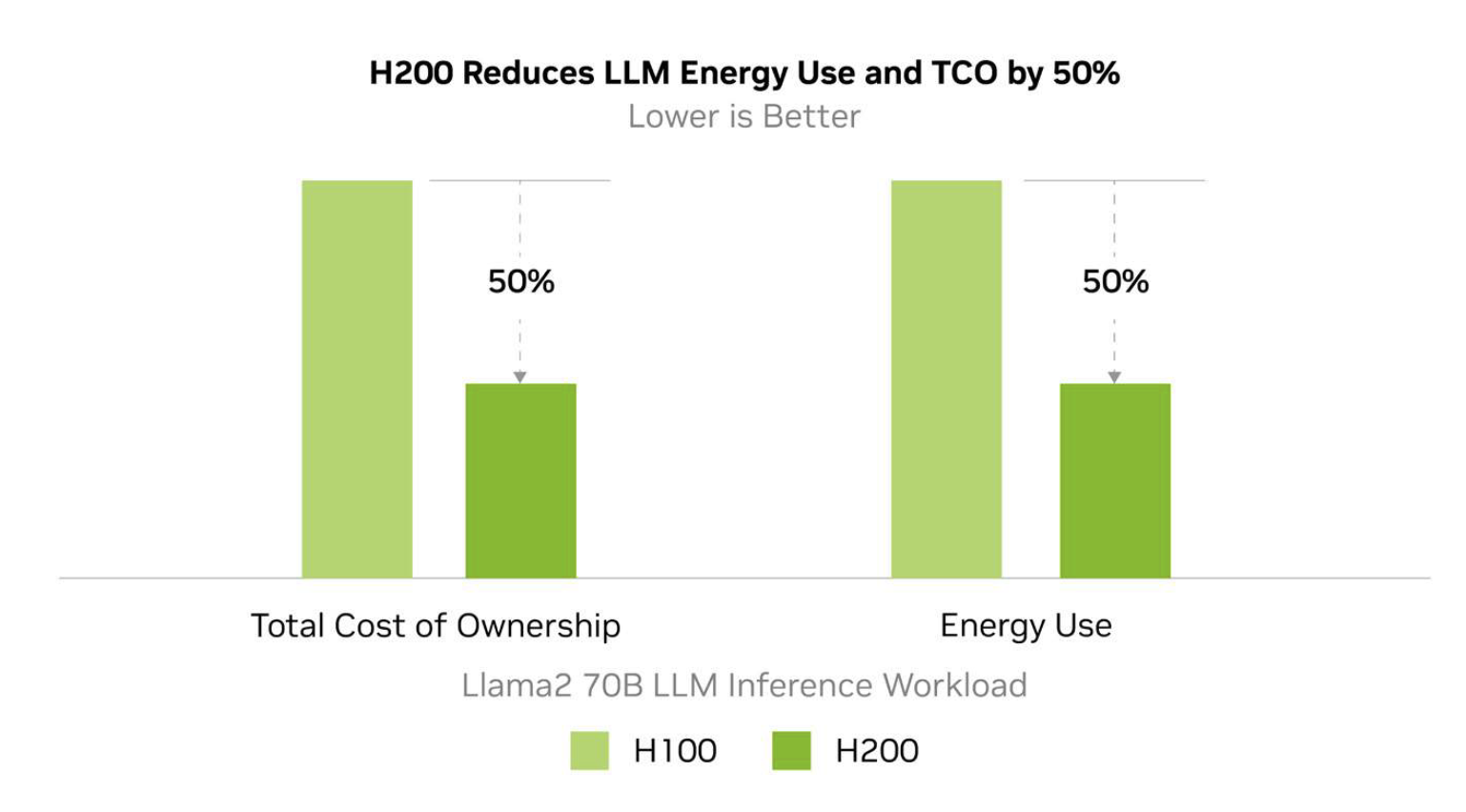
NVIDIA schätzt, dass der Energieverbrauch der H200 bei wichtigen LL-Inferenz-Workloads bis zu 50% niedriger sein wird als bei der H100, was zu 50% niedrigeren Gesamtkosten über die Lebensdauer des Geräts führt.
Der GH200 Superchip: Verwandt, aber Anders
Neben der H200 hat NVIDIA auch den GH200 Grace Hopper Superchip vorgestellt. Obwohl verwandt, ist der GH200 nicht identisch mit der H200. Der GH200 kombiniert eine NVIDIA Hopper-GPU (ähnlich der H200) mit der Grace-CPU und schafft so eine einheitliche Plattform, die eine massive Leistungssteigerung für komplexe KI- und HPC-Arbeitslasten bietet.
Der GH200 wurde speziell für Szenarien entwickelt, die eine enge Integration von CPU- und GPU-Ressourcen erfordern. Durch den Einsatz von NVIDIAs NVLink-C2C-Interconnect ermöglicht er eine schnelle Datenübertragung zwischen der Grace-CPU und der Hopper-GPU. Dieses Setup beschleunigt Arbeitsabläufe für Anwendungen wie großskalige KI-Modellschulungen, Datenanalysen und wissenschaftliche Simulationen.
Wesentliche Unterschiede zwischen GH200 und H200:
CPU-Integration: Der GH200 integriert die Grace-CPU zusammen mit der Hopper-GPU und bietet eine heterogene Computerplattform. Im Gegensatz dazu ist die H200 eine eigenständige GPU.
Speicherkapazität: Der GH200 verfügt über bis zu 480 GB HBM3e, verglichen mit den 141 GB der H200, was ihn besser geeignet macht für extrem große Datensätze.
Zielanwendungen: Der GH200 ist ideal für Arbeitslasten, die eine nahtlose CPU-GPU-Koordination erfordern, wie großskalige KI-Schulungen. Die H200 hingegen ist auf reine GPU-Berechnungsaufgaben optimiert.
Obwohl beide auf der Hopper-Architektur basieren und außergewöhnliche Leistung bieten, dienen der GH200 und die H200 unterschiedlichen Zwecken. Die H200 glänzt bei GPU-zentrierten Aufgaben, während der GH200 für Anwendungen entwickelt wurde, die eine enge Zusammenarbeit zwischen CPU und GPU erfordern.
Preise für H200-GPUs bei DataCrunch: Feste vs. Dynamische Preise
DataCrunch bietet zwei unterschiedliche Preisoptionen für H200-GPU-Instanzen: Feste Preise und Dynamische Preise. Diese Flexibilität ermöglicht es Ihnen, das beste Preismodell für Ihre Arbeitslasten und Budgetanforderungen auszuwählen.
Feste Preise: Der feste Preis für H200-GPU-Instanzen beträgt derzeit 3,59 $ pro Stunde. Dieser Tarif garantiert vorhersehbare Kosten und ist daher ideal für Projekte, die eine konsistente Budgetierung und Planung erfordern. Mit festen Preisen sichern Sie sich einen stabilen Tarif und vermeiden Preisschwankungen, was für Planungssicherheit sorgt.
Dynamische Preise: Alternativ bietet DataCrunch ein Modell mit dynamischen Preisen, das derzeit bei 2,62 $ pro Stunde beginnt. Die dynamischen Preise ändern sich basierend auf Angebot und Nachfrage nach GPU-Ressourcen in Echtzeit. Das bedeutet, dass Sie von niedrigeren Tarifen während weniger ausgelasteter Zeiten profitieren können. Während dieses Preismodell Einsparungen ermöglicht, bringt es auch die Möglichkeit von Preisschwankungen mit sich, wenn die Nachfrage nach GPU-Ressourcen steigt oder sinkt.
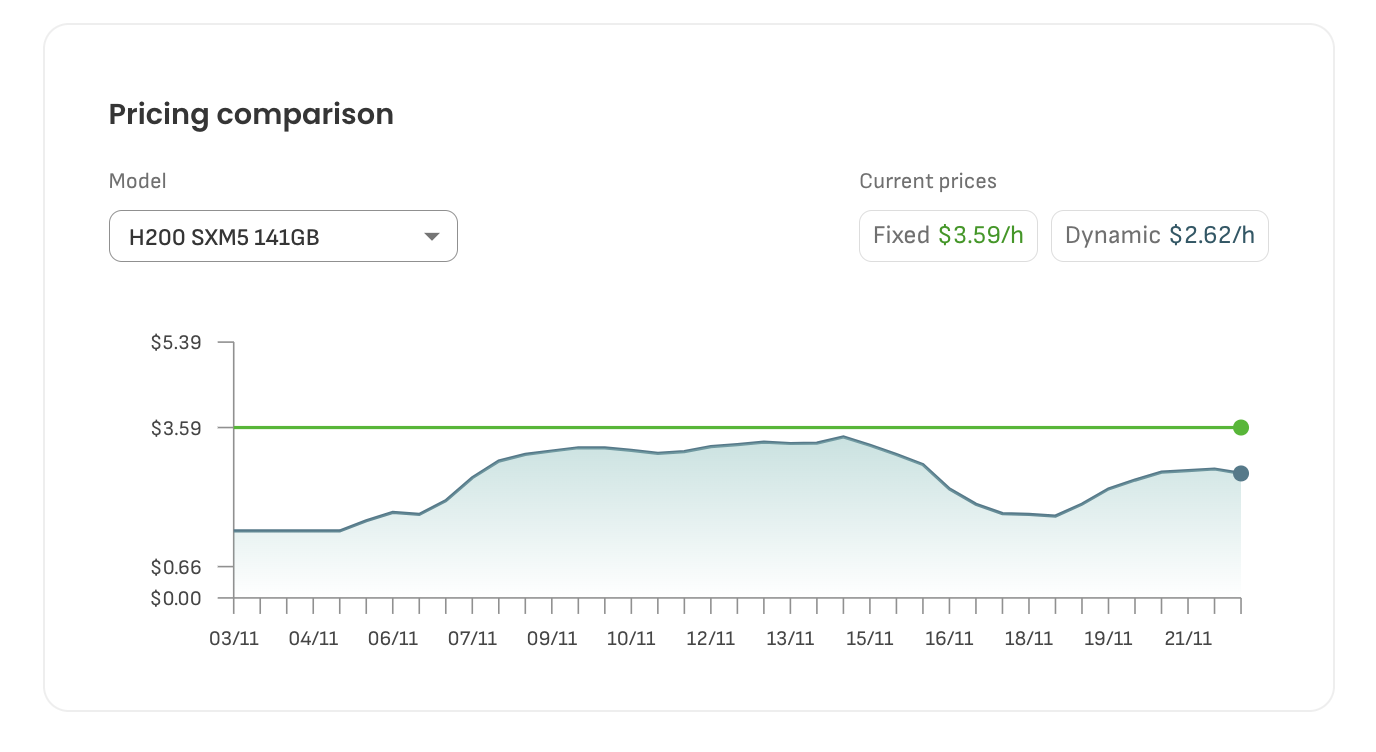
Die obenstehende Grafik zeigt aktuelle Preistrends für H200-GPU-Instanzen auf der DataCrunch-Plattform. Die dynamischen Preise schwanken täglich und werden von Faktoren wie der Verfügbarkeit von GPUs und der Marktnachfrage beeinflusst. Wenn Sie flexibel in der zeitlichen Planung Ihrer Arbeitslasten sind, kann das Modell der dynamischen Preise zu erheblichen Kosteneinsparungen im Vergleich zu festen Preisen führen.
Insgesamt bietet die Preisflexibilität von DataCrunch sowohl für diejenigen, die vorhersehbare Kosten bevorzugen, als auch für Nutzer, die bereit sind, für niedrigere Tarife zu optimieren, die passende Option, um die finanziellen und betrieblichen Anforderungen Ihres Projekts bestmöglich zu erfüllen.
H200s heute mit DataCrunch bereitstellen
Wenn Sie sich wie ein Kind fühlen, das auf Weihnachten wartet, sind Sie nicht allein. Die H200 verfügt über ideale Spezifikationen, um maschinelles Lernen und High-Performance-Computing auf ein neues Niveau zu bringen. Es wird noch eine Weile dauern, bis eine andere GPU mit überlegener Leistung und Kosteneffizienz verfügbar ist.
Die H200 löst die zentralen Effizienzprobleme der H100, was bedeutet, dass Sie eine höhere Speicherbandbreite bei einem geringeren Leistungs-pro-Watt-Verbrauch erhalten.
Die NVIDIA H200 GPU ist jetzt vollständig bei DataCrunch verfügbar – als 1x-, 2x-, 4x- und 8x-Instanzen sowie in dedizierten Clustern. Diese Flexibilität ermöglicht es Ihnen, Ihre Bereitstellungen an die Anforderungen Ihrer KI- und HPC-Arbeitslasten anzupassen, egal ob Sie eine einzelne Instanz für kleinere Aufgaben oder einen gesamten Cluster für großskaliges Training und Inferenz benötigen.
Bereit, die H200 auszuprobieren? Starten Sie noch heute eine Instanz!