
Während neue KI-Startups und Hyperscaler die Grenzen des Möglichen im Deep Learning weiter verschieben, war die Nachfrage nach Hochleistungs-KI-Computing noch nie so groß wie heute.
NVIDIA’s GB200 NVL72 stellt den nächsten großen Sprung in der datenzentrierten Technologie mit Fokus auf KI dar. Es ist die nächste Generation von enorm leistungsfähigem, hoch skalierbarem und energieeffizienterem Computing. Sicherlich haben Sie noch nie zuvor ein Rack wie dieses gesehen.

GB200 NVL72 Datacenter-Rack. Quelle: nvidia.com
Was ist die NVIDIA GB200?
Die NVIDIA GB200 NVL72 ist ein maßgeschneidertes Datacenter-Rack, das 36 Grace-CPUs und 72 Blackwell-GPUs enthält, die durch ein 130 TB/s NVLink-Switch-System verbunden sind.
Die GB200 NVL72 ist darauf ausgelegt, als eine kohärente und einheitliche GPU zu arbeiten, die in der Lage ist, die komplexesten KI- und Hochleistungsrechenlasten (HPC) mit außergewöhnlicher Effizienz und Geschwindigkeit zu bewältigen. GB200 NVL72 Architektur
Die GB200 NVL72 wird von NVIDIAs neuester Blackwell-GPU-Architektur angetrieben, die im Vergleich zu den vorherigen Ampere- und Hopper-Architekturen, welche die A100, H100 und H200 antreiben, einen signifikanten Leistungsschub bietet.

Der Blackwell-GPU-Chip. Quelle: nvidia.com
Innerhalb der GB200 NVL72 finden Sie 36 GB200-Superchips, bei denen eine Grace-CPU und zwei Blackwell-GPUs auf einer einzelnen Platine sitzen. Laut NVIDIA enthält jede Blackwell-GPU 208 Milliarden Transistoren, mehr als das 2,5-fache der Anzahl von Transistoren in den NVIDIA Hopper-GPUs.
GB200 Netzwerk- und Speicherbandbreitenkonnektivität
In den GB200 NVL72-Systemen werden voraussichtlich vier verschiedene Netzwerke zu finden sein:
Accelerator Interconnect (NVLink)
Out of Band Networking
Backend Networking (InfiniBand/RoCE Ethernet)
Frontend Networking (Normal Ethernet)
Quantum-X800 InfiniBand bildet die Grundlage des KI-Compute-Fabrics der GB200 und ist in der Lage, auf mehr als 10.000 GPUs zu skalieren, was 5-mal höher ist als die vorherige NVIDIA Quantum-2-Generation. Obwohl die meisten KI-Projekte nicht auf diesem Niveau skalieren werden, wird die GB200 voraussichtlich für längere Zeit der Maßstab für Rechenzentren-GPUs sein.
Blackwell-GPUs beinhalten 18 NVLink-Verbindungen der fünften Generation, die eine Gesamtbandbreite von 1,8 TB/s bieten, davon 900 GB/s in jede Richtung.

GB200 NVLink-System. Quelle: nvidia.com
Thermisches Energiemanagement
Die GB200 NVL72 ist eine leistungsstarke Maschine mit einem hohen Energiebedarf. Es wird voraussichtlich 120 kW pro Rack benötigen, was ungefähr dem Dreifachen eines luftgekühlten Racks mit H100s entspricht.
Dennoch umfasst die GB200-Architektur mehrere Verbesserungen im thermischen Energiemanagement, die den gesamten Energieverbrauch pro TFLOPS reduzieren. Sie verfügt über eine fortschrittliche Flüssigkeitskühlungslösung, die es ermöglicht, selbst unter hoher Belastung die Spitzenleistung aufrechtzuerhalten.

GB200-Rechenmodul mit Flüssigkeitskühlung. Quelle: nvidia.com
Der effektive Stromverbrauch pro GPU der GB200 beträgt effektiv 1200 Watt. Insgesamt schätzt NVIDIA, dass die GB200 NVL72 bei gleicher Leistung für Billionen-Parameter-KI-Modelle eine 25-mal bessere Energieeffizienz liefert als eine luftgekühlte H100-Infrastruktur.
GB200 NVL72 Spezifikationen im Vergleich zu H100 und H200
Der natürlichste Vergleich für die GB200 NVL72 ist mit den derzeit leistungsstärksten NVIDIA-GPUs auf dem Markt, der H100 und H200.
H100 | H200 | GB200 NVL72 | |
|---|---|---|---|
Watt (pro GPU) | 700 | 700 | 1.200 |
NVLink-Bandbreite (GB/s) | 450 | 450 | 900 |
Speicherkapazität (GB) | 80GB | 141GB | 192GB |
Speicherbandbreite (GB/s) | 3.352 | 4.800 | 8.000 |
TF32 TFLOPS | 495 | 495 | 1.250 |
FP16/BF16 TFLOPS | 989 | 989 | 2.500 |
FP8/FP6/Int8 TFLOPS | 1.979 | 1.979 | 5.000 |
FP4 TFLOPS | 1.979 | 1.979 | 10.000 |
Quelle: nvidia.com, SemiAnalysis
*Erhalten Sie eine detailliertere Zusammenfassung der H100- und H200-Spezifikationen.
KI-Leistungszusammenfassung
Die GB200 NVL72 bietet bis zu 30-mal höhere Durchsatzraten bei KI-bezogenen Aufgaben als die H100, insbesondere bei dichten Matrixoperationen. Optimierungen von NVIDIA helfen, die Latenz zu reduzieren und die Effizienz in Multi-GPU-Konfigurationen zu erhöhen, was zu einer bis zu 4-mal schnelleren GPT-Moe-1.8T-Modelltrainingszeit im Vergleich zur H100 führt.
Vergleich des GB200 NVL72-Systems mit einer H100. Quelle: nvidia.com
Insgesamt kann das GB200 NVL72-System 1,44 ExaFLOPS superniedrigpräzise Gleitkomma-Mathematik ausführen und ist damit die erste Exascale-GPU-Lösung.
In einem realen Beispiel benötigte OpenAI 90 Tage, um GPT-4 mit 25.000 A100s zu trainieren. Mit einem Setup von 100.000 GB200 NVL72 sollte es möglich sein, GPT-4 in weniger als 2 Tagen zu trainieren.
Neue Präzisionsfähigkeiten mit der zweiten Generation der Transformer Engine
Die GB200 NVL72 verwendet NVIDIAs zweite Generation der Transformer Engine, um fortschrittliche Präzisionsformate einzuführen, darunter auch von der Community definierte Microscaling-Formate wie MX-FP6, um sowohl die Genauigkeit als auch den Durchsatz für große Sprachmodelle (LLMs) und Mixture-of-Experts (MoE)-Modelle zu verbessern.
Mikro-Tensor-Skalierung nutzt das Management des Dynamikbereichs und feinkörnige Skalierungstechniken, um die Leistung und Genauigkeit zu optimieren, was den Einsatz von FP4-KI ermöglicht. Diese Innovation verdoppelt effektiv die Leistung mit Blackwells FP4 Tensor Core und erhöht außerdem die Parameterbandbreite zum HBM-Speicher, wodurch signifikant größere Modelle der nächsten Generation pro GPU möglich werden.
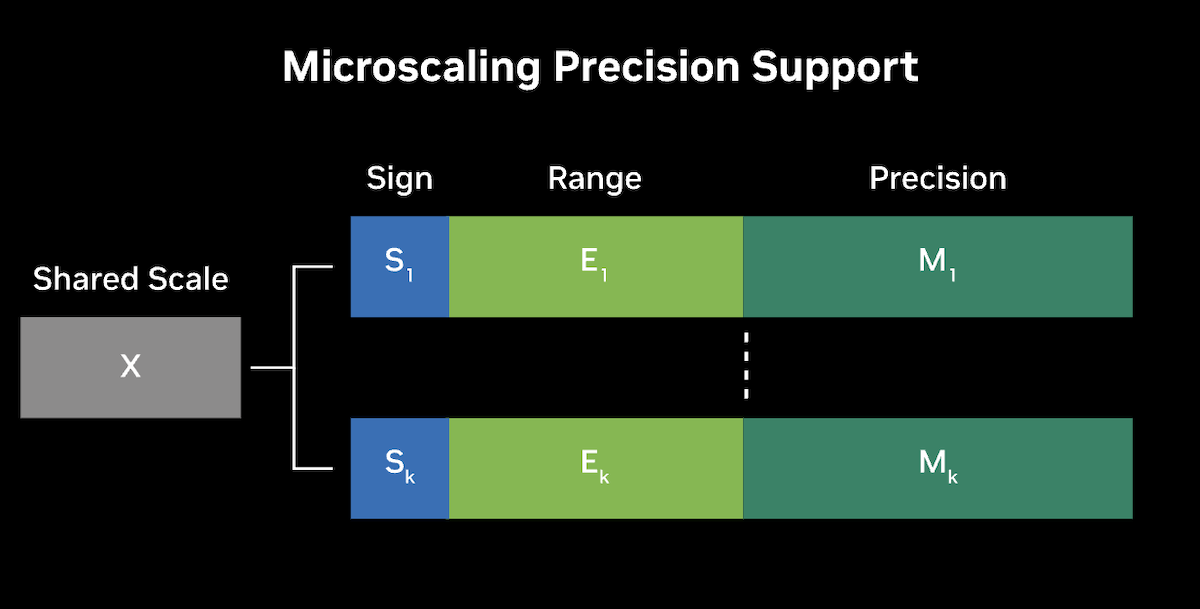
Konzeptioneller Rahmen für Mikroskalierungs-Präzision. Quelle: nvidia.com
Die Integration von TensorRT-LLM, mit Quantisierung auf 4-Bit-Präzision und benutzerdefinierten Kernen, ermöglicht die Echtzeit-Inferenz auf massiven Modellen mit reduziertem Hardwareeinsatz, Energieverbrauch und Kosten. Auf der Trainingsseite sorgen die zweite Generation der Transformer Engine, das Nemo Framework und die Megatron-Core PyTorch-Bibliothek durch Multi-GPU-Parallelismustechniken und Unterstützung der fünften Generation von NVLink für eine beispiellose Modellleistung.
Fazit zur GB200 NVL72
Die GB200 NVL72 ist anders als jedes Datacenter-Rack, das wir je gesehen haben. Ihre Fortschritte in der GPU-Architektur, der Speicherbandbreite und der Energieeffizienz machen sie zu einem leistungsstarken Werkzeug für die Bewältigung der anspruchsvollsten KI-Arbeitslasten. Für KI-Ingenieure bietet die NVL72 nicht nur überlegene Leistung, sondern auch die Flexibilität und Skalierbarkeit, die notwendig sind, um in einer schnelllebigen Branche wettbewerbsfähig zu bleiben.