
Die NVIDIA V100 ist ein legendäres Stück Hardware, das sich seinen Platz in der Geschichte des Hochleistungsrechnens verdient hat. Die 2017 eingeführte V100 brachte uns das Zeitalter der Tensor Cores und brachte viele Fortschritte durch die innovative Volta-Architektur.
In den letzten Jahren hat sich die Landschaft der KI-Hardware jedoch weiterentwickelt. Neuere Modelle wie die NVIDIA A100 und H100 sind auf den Markt gekommen und bieten überlegene Leistung und Fähigkeiten. Dies wirft eine wichtige Frage für KI-Ingenieure auf: Was ist der beste Einsatzzweck der V100 in der heutigen vielfältigen GPU-Landschaft? Lassen Sie uns diese Frage beantworten, indem wir die V100-Spezifikationen, die Leistung und die Preise aus heutiger Perspektive betrachten.
Einführung in die V100
Die im Mai 2017 eingeführte NVIDIA V100 markierte einen bedeutenden Meilenstein in der GPU-Branche. Es war die erste GPU, die auf NVIDIAs Volta-Architektur basierte, die mehrere bahnbrechende Technologien einführte, die darauf ausgelegt waren, KI- und Hochleistungsrechen- (HPC) Workloads zu beschleunigen. Die V100 war der Nachfolger der P100 und brachte erhebliche Verbesserungen in Leistung und Effizienz mit sich.
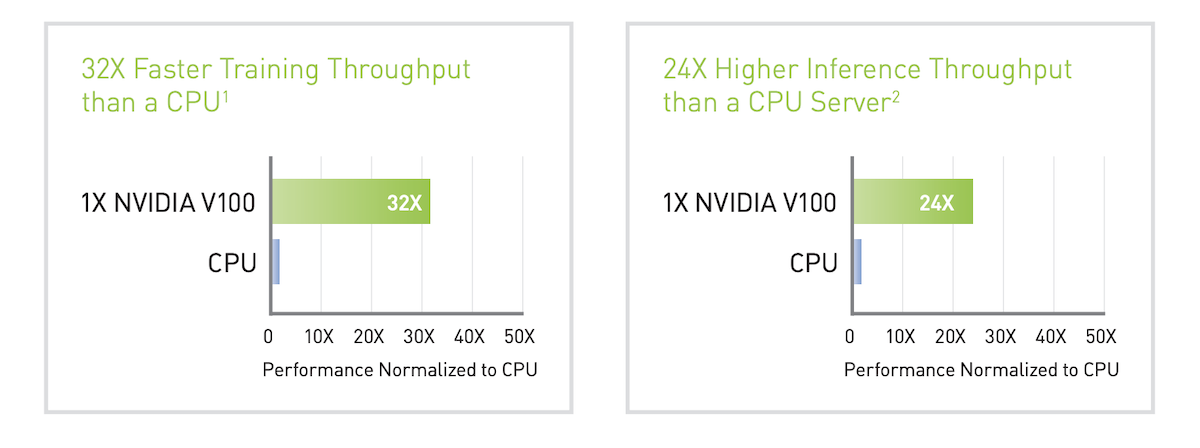
Zum Zeitpunkt der Markteinführung verglich NVIDIA auch die AI-Trainings- und Inferenzleistung der V100 mit einem Intel Gold 6240@2,6 GHz/3,9 GHz Turbo-CPU.
Volta-Architektur
Die V100 basiert auf der Volta-Architektur, die einen großen Fortschritt gegenüber früheren Generationen darstellt. Das Design von Volta konzentriert sich auf die Verbesserung der Parallelverarbeitungsfähigkeiten und der Energieeffizienz. Wichtige Merkmale umfassen eine neue Streaming-Multiprozessor- (SM) Architektur, eine neu gestaltete Speicherhierarchie und die Einführung von Tensor Cores.
Tensor Cores
Eines der Hauptmerkmale der V100 ist die Integration von Tensor Cores, spezialisierter Hardware, die darauf ausgelegt ist, Tensoroperationen zu beschleunigen, die für das Deep Learning wesentlich sind. Tensor Cores ermöglichen die gemischte Präzisionsberechnung, sodass die V100 Matrixmultiplikationen in beispielloser Geschwindigkeit durchführen kann. Dies führt zu erheblichen Leistungssteigerungen bei Aufgaben wie dem Training und der Inferenz neuronaler Netze.
Energieverbrauch und thermisches Design
Mit einer TDP von 300 Watt ist die V100 darauf ausgelegt, hohe Leistung bei gleichzeitiger Energieeffizienz zu liefern. Die Kühllösungen der GPU sind darauf ausgelegt, diesen Energieverbrauch effektiv zu verwalten und einen stabilen Betrieb auch unter schweren Rechenlasten zu gewährleisten.
Wichtige V100-Spezifikationen
Zum Zeitpunkt ihrer Einführung war die V100 die fortschrittlichste GPU der Welt. Obwohl sie mittlerweile von vielen neueren Modellen in den Spezifikationen übertroffen wurde, verfügt sie immer noch über solide Spezifikationen, die Hochleistungsrechnen ermöglichen.
Hier ist ein Datenblatt dessen, was Sie von der V100 GPU erwarten können:
CUDA-Kerne: 5.120
Tensor-Kerne: 640
Basistaktgeschwindigkeit: 1.215 MHz
Boost-Taktgeschwindigkeit: 1.380 MHz
Speicher: 16 GB oder 32 GB HBM2
Speicherbandbreite: 900 GB/s
TDP (Thermal Design Power): 300 Watt
Wie sich die V100 mit der P100 vergleicht
Als erste GPU überhaupt mit Tensor Cores ist es schwierig, die V100 mit früheren Modellen zu vergleichen. Der natürlichste Vergleich ist jedoch mit der P100, die die Pascal-Architektur nutzt. Im Vergleich zur P100 brachte die V100 einen erheblichen Anstieg der CUDA Cores (5.120 vs. 3.584) und eine deutliche Erhöhung der Speicherbandbreite (900 GB/s vs. 720 GB/s).
Dank der Tensor Core-Technologie war die V100 die erste GPU weltweit, die die 100-TeraFLOPS-(TFLOPS)-Marke in der Deep-Learning-Leistung durchbrach. Laut NVIDIA-Benchmarks kann die V100 Deep-Learning-Aufgaben 12-mal schneller als die P100 ausführen.
A100-Datenblattvergleich mit V100 und H100
Heute ist der natürlichste Vergleich mit den Spezifikationen der A100 und H100. In diesem Vergleich schneidet die V100 in vielen wichtigen Elementen schlechter ab.
GPU-Merkmale | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU-Board-Formfaktor | SXM2 | SXM4 | SXM5 |
SMs | 80 | 108 | 132 |
TPCs | 40 | 54 | 66 |
FP32-Kerne / SM | 64 | 64 | 128 |
FP32-Kerne / GPU | 5020 | 6912 | 16896 |
FP64-Kerne / SM (ohne Tensor) | 32 | 32 | 64 |
FP64-Kerne / GPU (ohne Tensor) | 2560 | 3456 | 8448 |
INT32-Kerne / SM | 64 | 64 | 64 |
INT32-Kerne / GPU | 5120 | 6912 | 8448 |
Tensor-Kerne / SM | 8 | 4 | 4 |
Tensor-Kerne / GPU | 640 | 432 | 528 |
Textureinheiten | 320 | 432 | 528 |
Speicherinterface | 4096-bit HBM2 | 5120-bit HBM2 | 5120-bit HBM3 |
Speicherbandbreite | 900 GB/s | 1555 GB/s | 3000 GB/s |
Transistoren | 21,1 Milliarden | 54,2 Milliarden | 80 Milliarden |
Maximale thermische Verlustleistung (TDP) | 300 Watt | 400 Watt | 700 Watt |
*Siehe detaillierte Vergleiche von V100 vs A100 und A100 vs H100.
V100 Leistungsmetriken
Die V100 ist in verschiedenen Leistungsmetriken immer noch ein solider Performer und eignet sich sowohl für das Training als auch für die Inferenz von Deep-Learning-Modellen:
FP32 (Einzelpräzision) Leistung:
15,7 TFLOPS
FP64 (Doppelpräzision) Leistung:
7,8 TFLOPS
Diese Metriken unterstreichen die Vielseitigkeit der V100, da sie eine hohe Leistung für verschiedene Präzisionsstufen liefert, die von unterschiedlichen KI-Anwendungen benötigt werden.
Einschränkungen der V100
Der größte Nachteil der V100 ist, dass sie den BF16- (oder bfloat16-) Datentyp nicht unterstützt. Dies erschwert das Training der heutigen größeren Modelle mit der V100. Trotzdem hat die V100 ihren Einsatz sowohl bei der Inferenz als auch beim Feintuning, da sie im Vergleich zu neueren GPUs zu vergleichsweise niedrigen Kosten gut verfügbar ist.
V100 Anwendungsfälle heute
Die V100 wurde in verschiedenen Branchen und Anwendungen weit verbreitet. Hier sind einige Beispiele:
Deep-Learning-Training: Sie können die V100 weiterhin für das Training kleinerer Deep-Learning-Modelle verwenden, insbesondere solcher, die keine BF16-Präzisionsunterstützung erfordern.
Inferenzaufgaben: Die Fähigkeit der V100, Hochdurchsatz-Inferenzaufgaben zu bewältigen, macht sie geeignet für den Einsatz von trainierten Modellen in Produktionsumgebungen.
Hochleistungsrechnen: Über die KI hinaus kann die V100 in der wissenschaftlichen Berechnung, bei Simulationen und anderen HPC-Anwendungen aufgrund ihrer Doppelpräzisionsleistung eingesetzt werden.
Bekanntlich verwendete OpenAI (mit Unterstützung von Microsoft) 10.000 V100s, um das Sprachmodell GPT-3 zu trainieren.
NVIDIA V100 Preisgestaltung
Heute finden Sie die NVIDIA V100 als einzelne Instanzen sowie als Cluster von bis zu 8 NVLink-verbundenen GPUs. In den letzten Jahren ist der Preis der V100 gesunken, was bedeutet, dass Sie On-Demand von Cloud-GPU-Anbietern wie DataCrunch basierend auf Ihren einzigartigen Bedürfnissen und Anforderungen erhalten können.
Bei einer kürzlich durchgeführten Überprüfung der Preise für Cloud-GPUs haben wir festgestellt, dass der Kostenunterschied zwischen Hyperscalern wie Amazon AWS, Google Cloud Platform und Microsoft Azure bis zu 8-mal höher war als bei unabhängigen AI-Computing-Spezialisten wie DataCrunch.
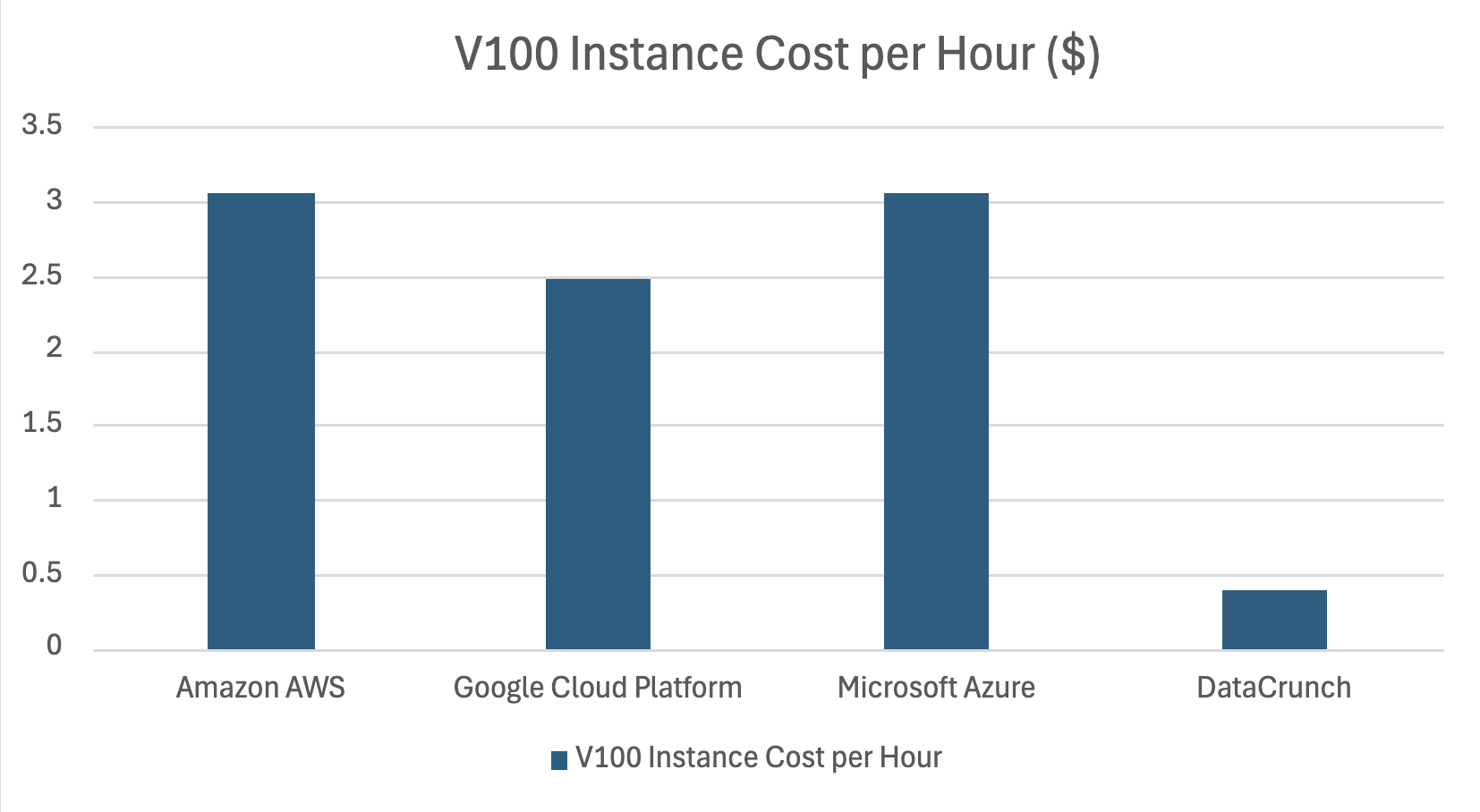
Aktuelle On-Demand-Preise für V100-Instanzen bei DataCrunch:
1 x V100 16GB:
$0,39/Stunde
4 x V100 16GB:
$1,56/Stunde
8 x V100 16GB:
$3,12/Stunde
Siehe Echtzeitpreise für V100.
Fazit zur V100
Die V100 ist eine legendäre GPU mit einem verdienten Platz unter den einflussreichsten Hardware-Komponenten in der Entwicklung der künstlichen Intelligenz.
Obwohl es von neueren Modellen wie dem A100 und dem H100 überschattet wurde, bleibt das V100 bis heute eine kosteneffiziente Lösung für Aufgaben wie Inferenz und Feinabstimmung von KI-Modellen. Sieh dir drei kreative Anwendungsfälle für das V100 an.
Wenn Sie die V100 ausprobieren möchten, starten Sie noch heute eine Instanz mit DataCrunch.