
If you’re running AI training or inference on NVIDIA hardware, you’re more than familiar with CUDA. What you may be less familiar with is the hardware acceleration CUDA Cores bring to today’s high-end NVIDIA GPUs.
In this article, we’ll review how CUDA Cores work, how they differ from Tensor Cores, and how they can accelerate your AI projects.
What Are CUDA Cores?
A CUDA Core is a small processing unit within many NVIDIA GPUs designed to execute computing tasks in parallel.
To put it simply, a CUDA Core is like a mini-CPU, but with one key difference: where a typical CPU has a limited number of cores, an NVIDIA GPU is packed with thousands of individual CUDA Cores. This massive parallelism allows a GPU to execute thousands of operations simultaneously, making it particularly useful for tasks that can be divided into smaller parts—such as matrix operations.
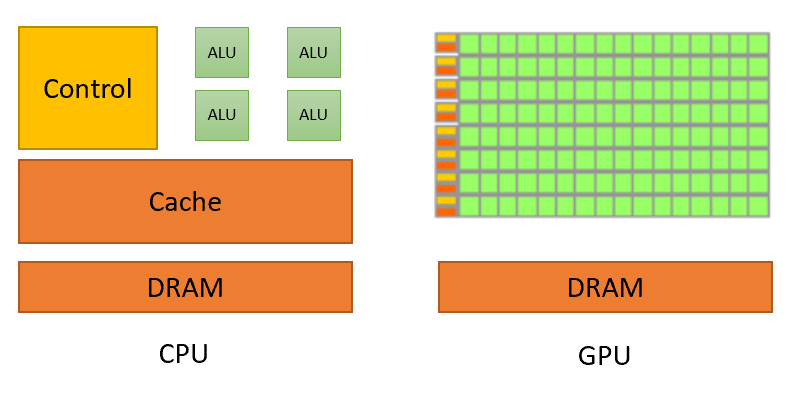
Visual representation of the difference between CPUs and GPUs. Source: nvidia.com
Background in CUDA programming model
NVIDIA introduced CUDA (Compute Unified Device Architecture) in 2006 as a platform and programming model to enable general-purpose parallel computing on its high-performance GPUs. CUDA Cores are the building blocks that make this possible by allowing a GPU to handle computations that go beyond graphics rendering.
Key ways CUDA Cores work
CUDA Cores operate based on the principle of parallelism. In AI and machine learning, this parallelism is a key advantage when dealing with large datasets. While a CPU might handle one or two tasks at a time, a GPU’s thousands of CUDA Cores can tackle hundreds or thousands of tasks concurrently, significantly speeding up the process.
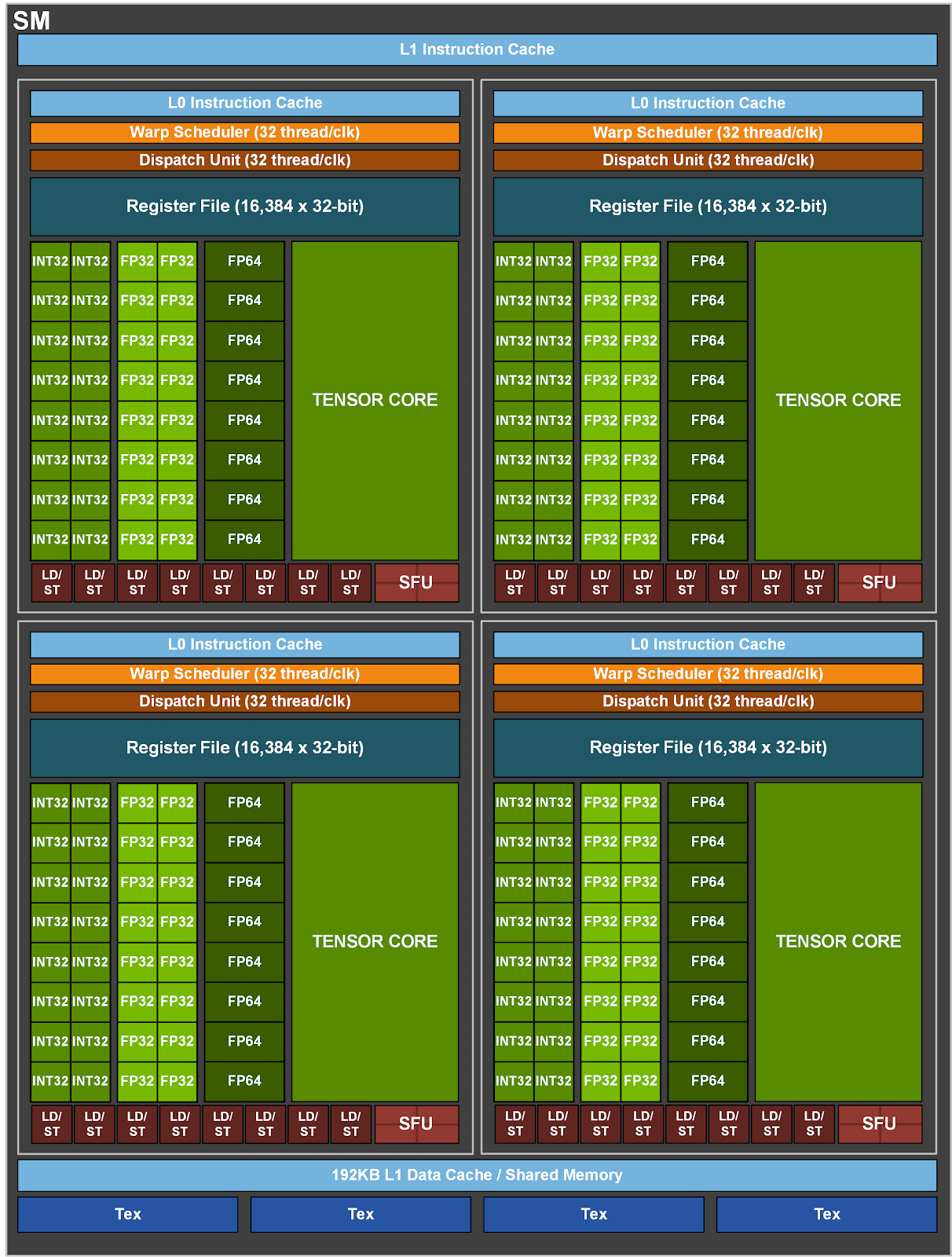
Illustration of the A100 streaming multiprocessor (SM) containing 64 CUDA Cores. Source: nvidia.com
Parallel Processing: One of the most important ways CUDA Cores accelerate tasks is through parallel processing. In a machine learning model, operations such as matrix multiplications, activations, and backpropagation can be processed in parallel. CUDA Cores distribute these operations across multiple threads, executing them simultaneously. This is especially beneficial when working with large datasets or models that require extensive computation.
Floating Point Operations: Machine learning models rely heavily on floating-point arithmetic, especially when calculating the weights and biases in neural networks. CUDA Cores are optimized to handle floating-point operations at incredible speeds. NVIDIA GPUs with CUDA Cores offer high throughput for single-precision (FP32) and double-precision (FP64) floating-point operations, which are common in machine learning and data science workloads.
Workload Distribution: Another crucial aspect of CUDA Core operation is workload management. When training a neural network, for instance, different portions of the dataset are processed in parallel, with CUDA Cores balancing the computational load across thousands of threads. This balance ensures that no core is left idle, leading to faster and more efficient processing.
Memory Access and Efficiency: CUDA Cores also play a crucial role in how a GPU accesses memory. When executing tasks, efficient memory access is critical to ensuring high performance. CUDA Cores operate within a well-organized memory hierarchy, which includes global memory, shared memory, and register memory. Global memory is the largest but slowest, while register memory is the fastest but limited in size. CUDA Cores, along with NVIDIA’s hardware architecture, manage the movement of data between these memory types to maximize efficiency. This enables faster data processing, which is crucial for AI models where large datasets are loaded and processed in parallel.
Threading and Block Management: NVIDIA’s CUDA architecture organizes threads into
blocks and grids to ensure tasks are managed effectively. When a computation is needed, CUDA Cores execute threads concurrently, and these threads are grouped into blocks. Each block is further organized into grids, ensuring that the workload is distributed evenly across CUDA Cores. This architecture allows large computations, like training a deep learning model, to be divided into smaller tasks and processed simultaneously. This means tasks that would take hours or even days on a CPU can be completed in a fraction of the time using GPUs with thousands of CUDA Cores.
How CUDA Cores align with deep learning frameworks
The CUDA platform is also supported by many of the popular AI and machine learning frameworks, like TensorFlow and PyTorch, which means that most AI engineers benefit from CUDA Cores even if they aren’t explicitly coding for it. This high-level integration abstracts away much of the complexity, allowing users to focus on building their models while the underlying GPU accelerates the heavy lifting.
CUDA Cores vs. Tensor Cores
While CUDA Cores are important for general-purpose parallel computation, Tensor Cores were introduced by NVIDIA in 2017 to further accelerate deep learning tasks, specifically matrix multiplications. Tensor Cores first appeared in NVIDIA’s Volta architecture (in GPUs like the Tesla V100) and have since been included in GPUs based on the Turing, Ampere, Hopper and Blackwell architectures.
Key Differences Between CUDA Cores and Tensor Cores
There are also some clear differences between the use cases, precision levels supported and AI-related performance between CUDA Cores and Tensor Cores you should be aware of.
General-Purpose vs. Specialized Computation:
CUDA Cores are versatile and can handle a wide range of computations, from simple arithmetic to complex algorithms. They excel at general-purpose tasks, making them suitable for a broad spectrum of workloads.
Tensor Cores, on the other hand, are specifically designed for deep learning tasks, focusing primarily on accelerating matrix operations. These operations are fundamental to the forward and backward passes in neural network training, making Tensor Cores an invaluable tool for deep learning applications.
Precision Levels:
CUDA Cores: These are optimized for single-precision (FP32) and double-precision (FP64) floating-point operations, which are the most common precision levels in traditional machine learning and scientific computing.
Tensor Cores: Tensor Cores, in contrast, support mixed-precision computing, particularly for half-precision (FP16) and integer (INT8) calculations. This enables models to train faster and consume less memory, without significantly sacrificing accuracy.
Performance in AI and Deep Learning:
Tensor Cores offer a significant speed advantage when it comes to deep learning tasks like training convolutional neural networks (CNNs) or transformers. They accelerate matrix multiplication and accumulation operations, which are at the heart of these models.
CUDA Cores, while still playing a vital role in AI workloads, don’t provide the same level of acceleration for deep learning tasks. However, they handle other aspects of the workload, such as data preprocessing, memory management, and non-matrix operations, making them equally important for a balanced performance in AI pipelines.
The number of Tensor Cores and/or CUDA Cores play in to the speed, efficiency and cost of your AI workloads, but it’s more likely that you’ll view the performance of a GPU as an entity. One great place to compare your options is MLPerf or some other authoritative benchmarking solution.
Which NVIDIA GPUs Utilize CUDA Cores?
CUDA cores are present in almost every modern NVIDIA GPU, from consumer-level graphics cards to enterprise-grade solutions designed for data centers. Let’s take a closer look at the types of GPUs that utilize CUDA Cores:
Consumer GPUs (GeForce Series):
NVIDIA’s GeForce series, such as the RTX 3080 or RTX 4090, is widely known for its gaming performance. However, these GPUs also feature a significant number of CUDA cores, making them suitable for AI research and experimentation. Developers and hobbyists often use these GPUs to prototype machine learning models before scaling up to more powerful hardware.
Professional GPUs (Quadro Series):
The Quadro series is NVIDIA’s line of professional-grade GPUs designed for tasks like computer-aided design (CAD), video editing, and AI. These GPUs are equipped with both CUDA cores and Tensor Cores, making them suitable for AI engineers working on more demanding workloads, such as model training and complex data simulations.
Data Center GPUs (Volta, Ampere, Hopper, Blackwell):
They are commonly used in data centers, cloud environments, and research institutions to handle large-scale AI projects.
Below is an outline of different NVIDIA GPUs Streaming Microprocessor and CUDA Core counts.
GPU | Streaming Multiprocessors (SMs) | CUDA Cores |
|---|---|---|
144 | 18,432 | |
144 | 18,432 | |
132 | 16,896 | |
114 | 14,592 | |
142 | 18,176 | |
142 | 18,176 | |
84 | 10,752 | |
108 | 6,912 | |
80 | 5,120 |
Notes:
GH200 and H200: These GPUs utilize the full NVIDIA Hopper GPU architecture with all 144 Streaming Multiprocessors (SMs) enabled. Each SM contains 128 CUDA Cores, resulting in a total of 18,432 CUDA cores.
H100: The H100 GPU typically comes in two versions. The SXM version has 132 SMs, each with 128 CUDA Cores, totaling 16,896 CUDA Cores. The PCIe version has fewer SMs and thus fewer CUDA Cores (14,592).
A100 (80GB and 40GB): Both memory configurations of the A100 have the same number of CUDA Cores—6,912. This comes from 108 SMs with 64 CUDA Cores each.
L40S and RTX 6000 Ada: Both GPUs are based on the Ada Lovelace architecture and feature 142 SMs with 128 CUDA Cores per SM, totaling 18,176 CUDA Cores.
A6000: This GPU is based on the Ampere architecture and has 84 SMs with 128 CUDA cores each, totaling 10,752 CUDA Cores.
V100: Based on the Volta architecture, the V100 has 80 SMs with 64 CUDA Cores each, resulting in 5,120 CUDA cores.
How many CUDA Cores do you actually need for different use cases?
The number of CUDA Cores required varies significantly based on your GPU use case. Playing graphics-intensive video games and basic content creation typically need between 1,500 to 10,000 CUDA Cores, while more demanding tasks like high-definition video editing, high-performance computing, data science, and training AI models benefit from 5,000 to 18,000 CUDA Cores.
The CUDA Core count reflects a single GPU's ability to handle parallel processing—more cores generally enhance performance for tasks that can utilize this parallelism. However, factors like GPU architecture (with newer architectures offering more efficient cores), memory bandwidth, memory size, and software optimization also critically impact overall performance. Specialized features like Tensor Cores and multi-GPU processing further accelerate workloads in AI training. In the end of the day, both hardware capabilities and software efficiency together determine the GPU's effectiveness for a given task - and simply counting CUDA Cores won’t get you very far.
Are there alternatives to CUDA Cores?
While AMD's Stream Processors and Intel's OneAPI offer alternative platforms for GPU computing, they currently fall short of matching NVIDIA's CUDA in AI workloads.
CUDA has established itself as the industry standard for GPU-accelerated computing in deep learning and artificial intelligence, boasting a mature ecosystem with highly optimized libraries like cuDNN and TensorRT, extensive developer tools, and strong community support.
In contrast, AMD and Intel are still developing their software ecosystems and hardware integration for AI applications. Their platforms lack the same level of optimization, comprehensive libraries, and widespread adoption, which makes them less competitive for AI workloads at present. While they provide viable options in other computing areas, they are far from matching CUDA's performance and efficiency in AI tasks.
Bottom Line on CUDA Cores
CUDA Cores are the unsung heroes of NVIDIA GPUs, enabling unparalleled parallelism and computation speed that make them essential for AI and data science workloads. From data preprocessing to neural network training and inference, CUDA Cores accelerate many of the most resource-intensive tasks AI engineers face.