
With so many high-performance GPUs launched by NVIDIA lately, it’s difficult to keep track of the unique benefits of each model.
The NVIDIA L40S has received less attention than many other GPUs, but it has found a unique position in high performance computing and specific deep learning use-cases.

Let’s go through what you need to know about the specs and performance of the L40S compared to two more popular models, the A100 and H100.
What is the L40S
The L40S is an adaptation of NVIDIA’s Ada Lovelace GPU architecture. You can consider it an upgraded version of the L40 and a distant relative of the RTX 4090 high-end gaming graphics card. The L40 was originally designed for data center graphics and simulation workloads. It found a new form of life in the form of the L40S because of the huge demand seen in for GPUs in machine learning training and inference.
The L40S was released in October 2022 and billed by NVIDIA as “the most powerful universal GPU.” On paper it is powerful indeed. It includes 4th Generation Tensor Cores, 142 RT Cores and 48GB GDDR6 memory optimized for graphics performance. It’s also compatible with NVIDIA’s Transformer Engine technology found in the Hopper-series architecture.
What’s the Difference Between the NVIDIA L40 and L40S?
The NVIDIA L40 and L40S share a common lineage, but the L40S represents a significant upgrade tailored for AI and enterprise workloads. While both GPUs leverage the Ada Lovelace architecture, the L40S offers enhanced performance, memory capacity, and optimized efficiency.
Key differences include:
Performance Boost: The L40S delivers higher TFLOPs for both FP32 and mixed-precision operations, making it better suited for intensive AI training and inference tasks.
Memory Advantage: The L40S features increased GPU memory, allowing it to handle larger datasets and more complex AI models compared to the L40.
Target Use Cases: The L40 is positioned as a versatile GPU for general-purpose workloads, including graphics and light AI applications. The L40S, on the other hand, is purpose-built for high-performance AI and enterprise deployments.
These upgrades make the L40S a compelling option for users seeking maximum performance in cloud environments, offering an ideal balance of power and efficiency for demanding AI workflows.
The L40S became popular due to lack of availability of both the A100 and H100. These two are also the best comparisons in terms of specs and performance.
L40S vs A100 vs H100 Specs Comparison
GPU Features | NVIDIA A100 | NVIDIA L40S | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU Architecture | Ampere | Ada Lovelace | Hopper |
GPU Board Form Factor | SXM4 | Dual Slot PCIe | SXM5 |
GPU Memory | 40 or 80GB | 48GB | 80GB |
Memory Bandwidth | 1.6 to 2 TB/sec | 864 GB/sec | 3.35 TB/sec |
CUDA Cores | 6912 | 18176 | 14592 |
FP64 TFLOPS | 9.7 | N/A | 33.5 |
FP32 TFLOPS | 19.5 | 91.6 | 67 |
TF32 Tensor Core Flops* | 156 | 312 | 183 | 366 | 378 | 756 |
FP16 Tensor Core Flops* | 312 | 624 | 362 | 733 | 756 | 1513 |
FP8 Tensor Core TFLOPS | N/A | 733 | 1446 | 3958 TFOPS |
Peak INT8 TOPS* | 624 | 1248 | 733 | 1446 | 1513 | 3026 |
L2 Cache | 40MB | 96MB | 50MB |
Max thermal design power (TDP) | 400 Watts | 350 Watts | 700 Watts |
*Without and with structured sparsity.
Looking for more details on your options? Explore A100 specs and H100 specs in more detail.
Performance Comparison
There are clear differences in performance between the L40S, A100, and H100 in FP64 (double-precision), FP32 (single-precision), and FP16 (half-precision) computations.
FP64 (Double-Precision)
The L40S does not natively support FP64. In applications that require high precision, the L40S may not perform as well as the A100 and H100. The H100, with its significantly higher FP64 performance, is particularly well-suited for these demanding tasks in today’s GPU landscape.
FP32 (Single-Precision)
In FP32 Tensor Core performance the L40S substantially outshines the A100 40GB and on paper it also has a good top line performance compared to the H100. However, in memory-intensive ML-related cases this performance is likely to be balanced out by the GPUs lower memory bandwidth compared to both the A100 80GB and the H100.
FP16 (Half-Precision)
The L40S, although capable, may not be the optimal choice for the most demanding AI/ML workloads. It has similar performance to the A100 40GB but is clearly outperformed by the A100 80GB and the H100.
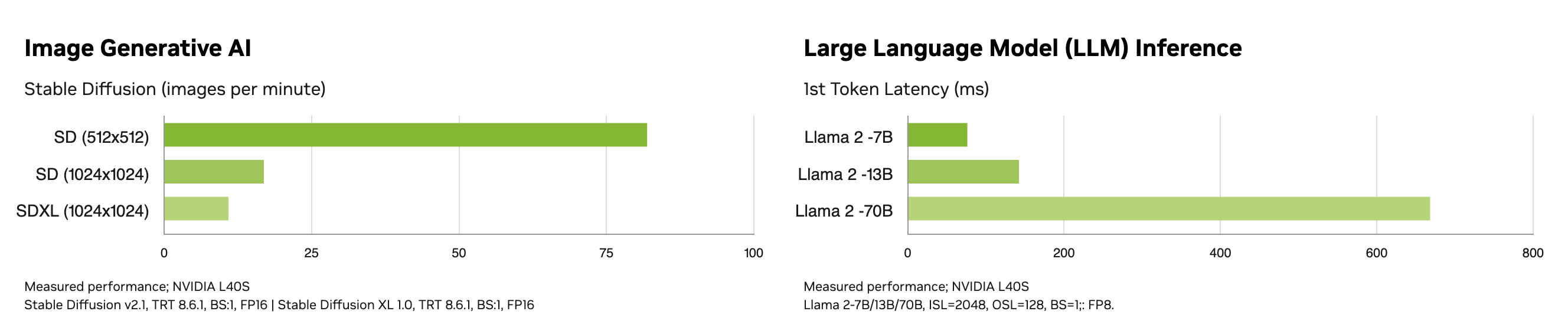
Lower memory bandwidth in the L40S
Theoretical peak FLOPS does not give you a full picture. For machine learning use cases memory bandwidth has a major role in training and inference. The L40S uses GDDR6 SGRAM memory, a common type of graphics random-access memory known for its balance of cost and performance. However, GDDR6 inherently has lower bandwidth capabilities compared to HBM (High Bandwidth Memory) solutions.
The A100 and H100, on the other hand, leverage HBM2e and HBM3, respectively. These HBM technologies offer significantly higher bandwidth due to their stacked architecture and wider data interfaces. This allows for a much faster data transfer rate between the GPU and its memory, which is crucial for high-performance computing tasks where large datasets are involved.
The L40S's GDDR6 memory, while suitable for general-purpose workloads, becomes a bottleneck when handling massive data transfers required for high-precision calculations and complex AI/ML models. The HBM implementations in the A100 and H100 address this bottleneck, enabling them to achieve significantly higher performance in those compute-intensive scenarios.
Power efficiency comparison
The L40S has a maximum thermal design power (TDP) of 350W, which is lower than both the A100 SXM4 (400W) and the H100 (700W). While lower power consumption can be better, this is not the case with high-performance computing. It's important to note that the L40S also has lower performance compared to the A100 and H100.
The H100, despite having the highest TDP, also offers the highest performance across all categories (FP16, FP32, and FP64). As a result, the H100 has better performance-per-watt than the A100 and L40S.
L40S Price Comparison with A100 and H100
While demand for high-performance GPUs remains high, the availability of L40S on cloud GPU platforms like DataCrunch is improving. Here is how it compares in cost per hour with the A100 and H100.
| ||||
|---|---|---|---|---|
On-demand instance | $1.29/hour | $1.10/hour | $1.75/hour | $2.65/hour |
↳ 2-year price | $0.97/hour | $0.83/hour | $1.31/hour | $1.99/hour |
8GPU On-demand instance | $10.32/hour | $8.80/hour | $14.00/hour | $21.20/hour |
↳ 2 year price | $7.74/hour | $6.60/hour | $10.50/hour | $15.90/hour |
Key point about costs: the price per hour of the L40S is comparable to the A100 40GB and is substantially lower than the H100 on a 2-year contract.
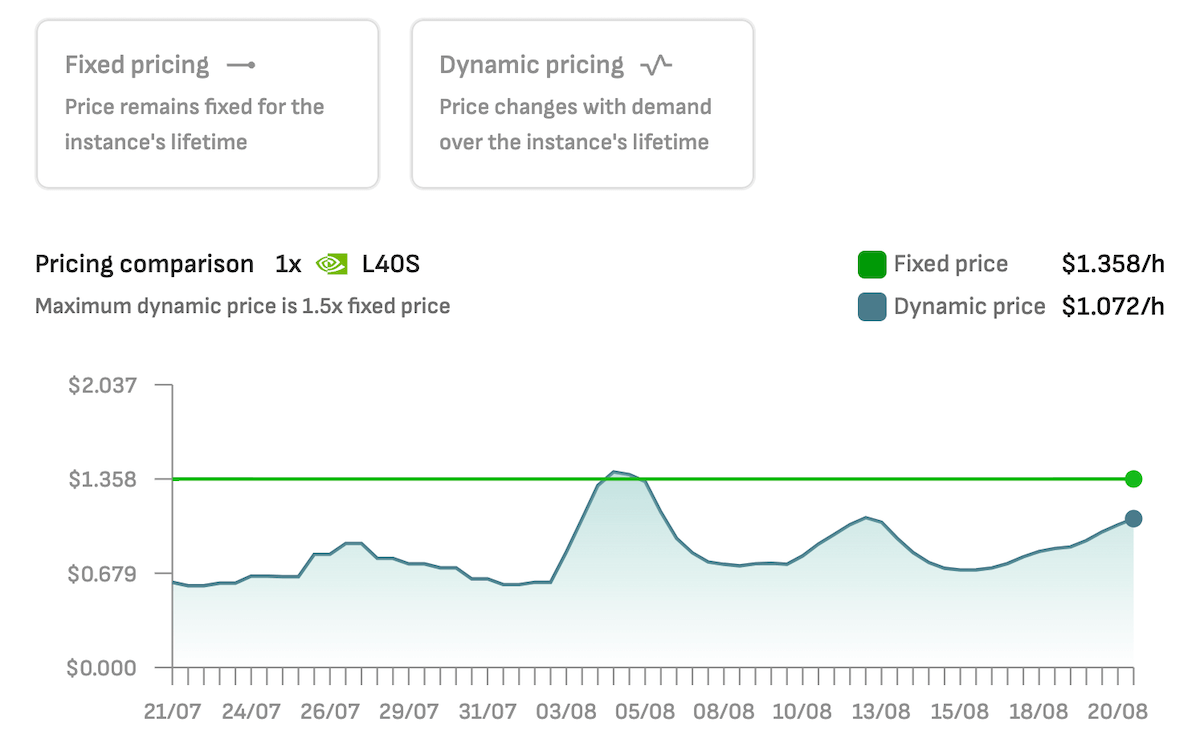
With DataCrunch you can also deploy the L40S using dynamic pricing, where the hourly price is often a lot lower.
Bottom line on the L40S
You can consider NVIDIA L40S as an outlier in today’s competitive field of computing accelerators. While it doesn’t have the raw performance capability of the H100 or new models, it has many areas where it compares favourably to the A100 and earlier GPUs.
L40S strengths
Versatile performance: The L40S aims to strike a balance between a high number of CUDA cores and RT Cores, making it suitable for a broader range of graphics-intensive workloads.
Large memory capacity: Its 48GB of GDDR6 memory gives it a small numerical edge over the A100 40GB, allowing it to handle some larger models (yet, with a lower memory bandwidth.)
L40S limitations
Raw computing power: For the absolute highest training throughput on massive models, the A100 or H100 hold an advantage due to their higher raw compute capabilities and high HBM memory bandwidth.
Lack of precision: the L40S is incapable of handling FP64, which can be an issue in matrix maths and training of many AI models.
In today’s market you shouldn’t dismiss the L40S. You can expect lower cost in the long term and better availability than the A100 80GB or the H100. It is a versatile GPU for machine learning projects where absolute compute speed is not your most important decision factor.