
Over the past few years we’ve seen massive breakthroughs in parallel computing thanks to hardware and software innovations like NVIDIA’s Tensor Core technology. Let’s break down what exactly are, how they work, and how they differ from CUDA Cores.
In the end of this article we’ll also explore which GPUs feature Tensor Cores and how you can use them for your AI projects—especially in scalable cloud environments.
GPU Hardware Acceleration
We all know AI workloads, particularly deep learning tasks, require vast amounts of matrix multiplication. The scale of the calculations needed in trillion parameter transformer model training would not be possible without hardware acceleration and parallel computing.
While a traditional Central Processing Unit (CPU) can handle these tasks, the sheer volume of computations quickly becomes overwhelming. This is where Graphics Processing Units (GPUs) come in. GPUs are designed for parallelism, making them much faster than CPUs for matrix-heavy tasks. But even within GPUs, there's room for specialized hardware acceleration of parallel computing, which is where Tensor Cores come into play.
What Are Tensor Cores?
Tensor Cores are specialized processing units found within certain NVIDIA GPUs such as the A100, H100 and H200 that are designed to accelerate deep learning tasks, particularly matrix operations.
The name “Tensor” comes from the mathematical object "tensor," which generalizes scalars, vectors, and matrices. Tensor computations are fundamental in AI models because neural networks represent weights and activations as multi-dimensional arrays (or tensors).

Conceptual representation of Tensor Cores in AI calculations for transformers. Source: nvidia.com
What makes Tensor Cores unique
A key feature of Tensor Cores is their ability to perform matrix multiplications with mixed-precision arithmetic. This means that Tensor Cores can compute matrix multiplications faster by combining half-precision floating-point numbers (FP16) and full-precision floating-point numbers (FP32). This approach offers a significant speedup without sacrificing much in terms of accuracy.
Tensor Cores are designed to accelerate matrix multiplications in a highly efficient manner. Their specialized nature means they can handle massive volumes of data at a fraction of the time it would take even high-end traditional GPU cores, such as CUDA Cores.
Tensor Cores are an essential part of making today’s neural networks more efficient, allowing us to train trillion parameter transformer models and deploy AI systems at scale.
What’s the benefit of Tensor Cores?
The core benefit of Tensor Cores is that they perform multiple operations in parallel, handling the massive volume of data that deep learning requires. In practical terms, Tensor Cores significantly reduce training times for models, enabling more iterations in a shorter period. This boost in speed can also translate into cost savings, especially in cloud environments like the DataCrunch Cloud Platform where you can pay based on hourly usage.

Illustration: H100 has up to 6x throughput for AI tasks compared to A100 thanks to 4th Generation Tensor Cores. Source: nvidia.com
How Do Tensor Cores Work?
Tensor Cores are designed to perform operations on 4x4 matrix tiles in a single clock cycle, while handling mixed-precision inputs.
For example, if you have a deep learning model that operates with FP32 precision, Tensor Cores can handle certain parts of the computation with FP16, speeding up the process without significantly impacting the accuracy of the results. This is particularly useful when dealing with very large datasets, as the speedup can drastically reduce training time.
Tensor Cores vs CUDA Cores
While both Tensor Cores and CUDA cores are integral to modern AI-focused NVIDIA GPUs, they serve different purposes.
CUDA Cores are general-purpose cores that can handle a wide range of parallel computing tasks, from 3D rendering to scientific simulations. In contrast, Tensor Cores are specialized hardware designed specifically for AI workloads.
The primary advantage Tensor Cores offer over CUDA Cores is their ability to perform mixed-precision matrix operations at a much higher throughput. Tensor Cores accelerate matrix multiplication and convolution operations, two key functions in deep learning models. While CUDA Cores can also handle these operations, they do so with standard precision and typically take more time for large matrices.
Mixed-Precision Advantage of Tensor Cores
In mixed-precision mode, Tensor Cores can combine FP16 (half-precision floating point) and FP32 (single-precision floating point) arithmetic, providing a balance between performance and precision. The use of FP16 allows for faster computation and reduced memory bandwidth, while FP32 ensures that critical parts of the computation retain higher precision. This combination speeds up training by a significant margin, enabling faster iterations on large models.
In summary:
CUDA Cores: Versatile, general-purpose processors for parallel tasks.
Tensor Cores: Specialized for deep learning, especially matrix-heavy computations like training neural networks. They’re faster for AI tasks and are optimized for mixed-precision arithmetic.
GPUs That Feature Tensor Cores
NVIDIA introduced Tensor Cores with the Volta architecture, starting with the V100 GPU, which was designed specifically for data centers and AI research. Since then, Tensor Cores have become a standard feature in several NVIDIA GPU families, each improving performance and making AI workloads more efficient.
Here’s a breakdown of the major GPU architectures featuring Tensor Cores:
Architecture | GPU Examples | Tensor Core Generation |
|---|---|---|
Volta | 1st Generation | |
Turing | RTX 20 Series | 2nd Generation |
Ampere | 3rd Generation | |
Ada Lovelace | 4th Generation | |
Hopper | 4th Generation | |
Blackwell | 5th Generation |
Each generation of Tensor Cores has improved the throughput and efficiency of deep learning workloads, making them faster and more power-efficient. Depending on your AI project, budget, and performance needs, you can choose from a range of GPUs to leverage Tensor Cores for training and inference tasks.
How Tensor Cores Impact AI Projects
Tensor Cores significantly change the game when it comes to AI training and inference. For Data Scientists, the most noticeable impact is the reduction in training time. Large AI models can take weeks or even months to train on traditional hardware, but with Tensor Cores, this process is accelerated by orders of magnitude.
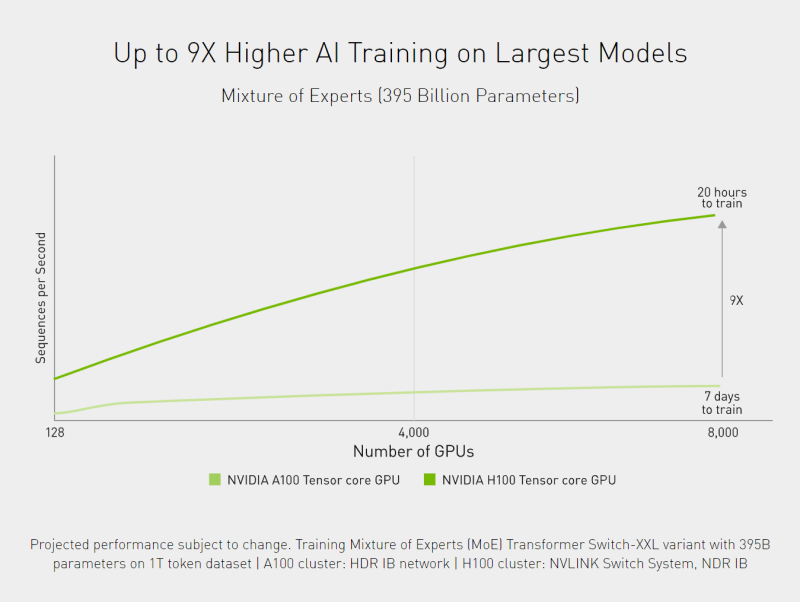
Example of up to 9x faster training times enabled by Tensor Core technology. Source: nvidia.com
In addition to reducing training times, Tensor Cores improve inference performance. When deploying AI models in production, the speed at which they can make predictions is critical, particularly in real-time applications like recommendation systems, autonomous vehicles, or voice recognition systems. Tensor Cores help ensure that these predictions happen with low latency, which is crucial for AI applications that demand real-time results.
Cloud GPUs and Tensor Cores
If you’re looking to train a new transformer model, the advantage of Tensor Cores stacks up well with the ability to use cloud GPUs on demand. Through Cloud GPU providers like DataCrunch you can access powerful parallel computing resources without the need for large capital investments in hardware.
One of the significant advantages of using cloud-based Tensor Core GPUs is the ability to tailor resource use to project needs. If you have a model that requires intensive training but only for a short duration, renting a cloud GPU instances with Tensor Cores can be a more cost-effective approach than purchasing physical hardware.
The key to cost-effectiveness is efficient resource management:
Choose the Right GPU:
Different AI workloads may benefit from different GPUs. For example, if your workload involves very large models, an NVIDIA H100 instance (with its fourth-generation Tensor Cores) may be ideal due to its ability to handle massive datasets and models. On the other hand, if you're running smaller models, the V100 could be more than sufficient at a lower cost-per-hour.
Utilize Dynamic Pricing Instances:
For non-urgent tasks like smaller model training, using dynamic pricing can lead to significant cost savings.
Leverage Mixed-Precision Training:
Whenever possible, use mixed precision support for Tensor Core-enabled instances. This can optimize performance by utilizing the FP16 precision where possible and FP32 where needed, improving speed without a loss of model accuracy.
NVIDIA Libraries and Tools Supporting Tensor Cores
NVIDIA provides several libraries that make it easier to leverage Tensor Cores. These libraries are optimized for deep learning workloads and ensure that Tensor Cores are used efficiently:
cuBLAS and cuDNN: NVIDIA’s cuBLAS (Basic Linear Algebra Subprograms) and cuDNN (Deep Neural Network) libraries are highly optimized for AI workloads. They handle low-level matrix operations and ensure Tensor Cores are used when performing tasks like convolutions and matrix multiplications.
TensorRT: TensorRT is an inference optimization toolkit by NVIDIA, designed to take advantage of Tensor Cores when deploying AI models for inference. TensorRT helps optimize trained models by reducing memory use and latency, making it especially useful for real-time applications.
By using these tools you can ensure that their AI models are optimized to run efficiently on Tensor Core GPUs, reducing training and inference times.
Adjusting Model Architecture
Another way to optimize Tensor Core usage is by adjusting your model architecture. When working with Tensor Cores, larger batch sizes can lead to more significant speedups. This is because Tensor Cores process operations in parallel, and larger batches allow them to maximize their throughput. Experimenting with larger batch sizes, however, will depend on your hardware’s memory limits and the specific nature of your model.
Challenges and Considerations
While Tensor Cores offer significant advantages for AI workloads, there are a few challenges and considerations to keep in mind:
Not All Models Benefit Equally: Tensor Cores are most effective when performing large-scale matrix operations, which are common in deep learning. However, for non-deep learning tasks or models with smaller matrices, Tensor Cores may not provide a noticeable performance boost over CUDA Cores.
Framework Compatibility: To fully benefit from Tensor Cores, your deep learning framework must support mixed-precision training. While major frameworks like TensorFlow and PyTorch have excellent support, older or less commonly used frameworks may not be optimized for Tensor Core use.
GPU Memory: Mixed-precision training reduces memory usage, but large models or batch sizes can still overwhelm the GPU’s memory. You may need to manage batch sizes and memory usage carefully to avoid out-of-memory errors.
Bottom Line on Tensor Cores
Tensor Cores are a core component of efficient parallel computing, particularly helpful in large-scale deep learning. They accelerate matrix operations and improve both training and inference times, making it possible to work with larger models and datasets more efficiently. The combination of mixed-precision training, NVIDIA’s software ecosystem, and cloud platforms like DataCrunch allows for unparalleled flexibility and scalability.
If you have questions about how you can deploy Tensor Cores in your deep learning projects, reach out to our AI engineers for advice.