
When the Nvidia V100 was launched back in 2017, it represented the pinnacle of high-performance GPU technology. It has played an integral part in the development of groundbreaking AI models like GPT-2 and GPT-3. Let’s not forget the V100 also started the revolution in Tensor Core chip design.
Today the V100 may not match the raw compute power and speed of the A100 and H100, but it still holds significant value for specific applications. Let’s go through a fresh performance comparison and three creative use cases for the V100 in the current GPU landscape for AI training and inference.
NVIDIA V100 Tensor Core GPU
The NVIDIA V100 was the first Volta-series GPU introduced by NVIDIA in 2017. At the time it marked a significant leap in GPU technology with the introduction of Tensor Cores. These cores were specifically designed by NVIDIA to accelerate matrix operations in deep learning and AI workloads in a compute-intensive datacenter setting.
Training speed: the V100 saw up to 12x performance improvement for deep learning training compared to NVIDIA's Pascal-series GPUs.
Memory: the V100 comes with 16 GB of HBM2 memory, with a memory bandwidth up to 900 GB/s.
Performance: With 640 Tensor Cores and 5,120 CUDA Cores, the V100 overall delivers 125 teraflops of deep learning (FP16) performance.
There is no doubt the V100 is a powerful and versatile GPU for AI projects. Famously OpenAI used over 10,000 V100s in the training of the GPT-3 large language model used in ChatGPT. However, its performance pales in comparison to more modern high-performance GPUs.
V100 vs A100 vs H100 Datasheet Comparison
GPU Features | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|---|
Form Factor | SXM2 | SXM4 | SXM5 |
Memory | 16 GB | 40 or 80 GB | 80 GB |
Memory Interface | 4096-bit HBM2 | 5120-bit HBM2 | 5120-bit HBM3 |
Memory Bandwidth | 900 GB/sec | 1555 GB/sec | 3000 GB/sec |
Transistors | 21.1 billion | 54.2 billion | 80 billion |
Power | 300 Watts | 400 Watts | 700 Watts |
* see more detailed comparisons of the V100 and A100 and A100 vs H100
By simply looking at technical specifications, the A100 and H100 are obviously better options for most deep learning projects. The V100 will not give you the high memory bandwidth and VRAM required by today’s most advanced AI models. If budget is not a major constraint, you should go for more powerful options for both speed and total cost of ownership.
Three creative use-cases for V100
While the A100 and H100 are generally better options, two factors go in the favour of the V100 – on-demand cost and availability.
Cost: The cost-per-hour of the V100 on cloud GPU platforms like DataCrunch has decreased significantly over the past year. Single GPU instances start as low as $0.39 per hour.
Availability: While A100s and H100s remain in more limited supply, you can secure 8-GPU instances and even larger clusters of V100s relatively easily and flexibly.
With these two factors in mind, here are three creative use cases where the V100 can be a credible option for your AI training or inference projects.
1. Multi-GPU coordination and scaling with NVLINK
One of the standout features of the V100 is its NVLINK capability, which allows multiple GPUs to communicate directly, bypassing the CPU for significant speed improvements in data transfer. This makes the V100 a credible choice for setting up a testbed for multi-GPU systems.
In a recent example our AI engineers experimented with a GPT-2 model featuring 124 million parameters using PyTorch’s native data parallelism, it was evident that although the setup was approximately seven times slower than an 8x H100 configuration, the coding practices and scalability lessons learned were directly transferable. This makes V100 a cost-effective platform for developers to prototype and refine multi-GPU applications before scaling up to more powerful, but also more expensive, systems.
2. GPU-accelerated data science with RAPIDS
Another potential use-case is using the V100 for small-scale data science projects through a GPU-accelerated data science framework like RAPIDS. RAPIDS, developed by NVIDIA, leverages CUDA to accelerate data science workflows by enabling data manipulation and computation directly on GPUs. Using a V100 can significantly speed up data preprocessing, model training, and visualization tasks within the RAPIDS framework, making it ideal for small to medium-scale data science projects. The cost-effectiveness of V100 compared to more powerful GPUs can make it a credible option for smaller scale RAPIDS projects.
3. Fine-tuning smaller AI models
The NVIDIA V100 also remains a good option for fine-tuning older AI models like GPT-2 due to its sufficient computational power and cost-effectiveness. With its 5,120 CUDA cores and specialized Tensor Cores, the V100 can handle many mixed-precision training cases. Additionally, the V100's compatibility with popular deep learning frameworks such as PyTorch and TensorFlow simplifies the integration into existing workflows. This makes it a credible choice for researchers and developers looking to refine and adapt older models without the need for more expensive hardware like the A100 or H100.
Bottom line on the V100 today
It’s too early to bury the V100 as a legacy solution. While newer models like the A100 and H100 offer superior performance, the Nvidia V100 still presents a compelling option for certain scenarios due to its cost-effectiveness, feature set, and compatibility with older systems.
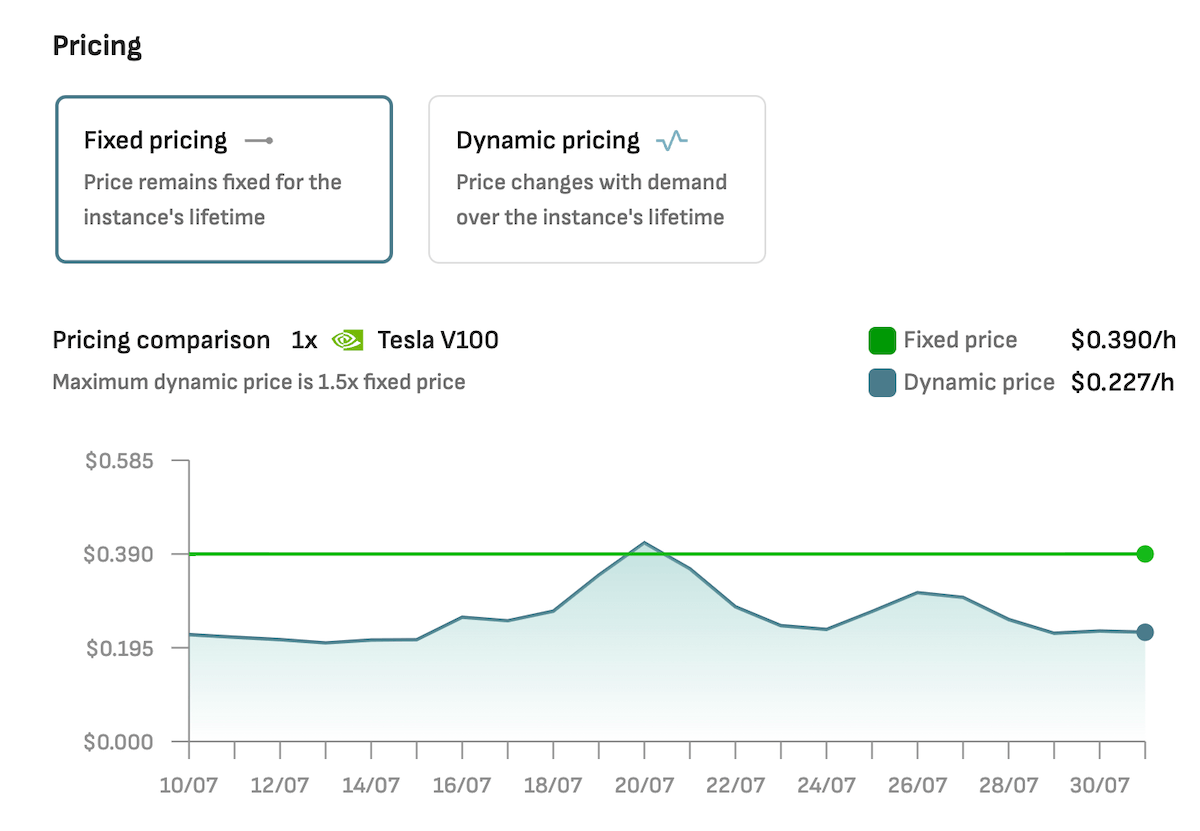
You can choose fixed or dynamic pricing for deploying NVIDIA V100 on the DataCrunch Cloud Platform.
NVIDIA V100 Pricing on DataCrunch
The NVIDIA Tesla V100 16GB is available on DataCrunch with flexible pricing options tailored to your workload needs. V100 pricing varies based on the instance size and commitment period:
On-Demand Pricing: Starts at $0.39/hour for a single GPU instance (1V100.6V) and goes up to $3.12/hour for an 8-GPU instance (8V100.48V).
6-Month Commitment: Discounts lower the price slightly, with the highest-tier instance priced at $3.00/hour and the smallest at $0.37/hour.
2-Year Commitment: The most significant savings come with a two-year commitment, where prices drop to as low as $0.29/hour for a single GPU and $2.34/hour for the 8-GPU instance.
All instances feature NVLink (up to 50GB/s bandwidth) for multi-GPU configurations, ensuring high-speed communication for demanding workloads. Whether you're running single-GPU tests or large-scale AI training, DataCrunch's flexible plans provide competitive pricing for the V100 GPU.
The V100 can handle tasks like multi-GPU experimentation, GPU-accelerated data science, or smaller AI model fine-tuning. If you’re looking to see what the V100 is capable of at a competitive price-point, spin up an instance on DataCrunch today!