
Wenn Sie nach den leistungsstärksten GPUs für maschinelles Lernen im Training oder in der Inferenz suchen, dann schauen Sie sich die NVIDIA H100 und A100 an. Beide sind äußerst leistungsstarke GPUs zur Skalierung von KI-Workloads, aber es gibt wesentliche Unterschiede, die Sie kennen sollten.
NVIDIA H100 (Hopper-Architektur)
Die NVIDIA H100 ist die erste ML-optimierte GPU, die die Hopper-Architektur verwendet, welche stark darauf ausgelegt ist, KI-Berechnungen zu beschleunigen. Die Architektur bringt erhebliche Verbesserungen mit sich, wie z.B. die 4. Generation der Tensor Cores, die für KI optimiert sind, insbesondere für Aufgaben im Bereich Deep Learning und große Sprachmodelle.
Zudem hat die H100 die Transformer Engine eingeführt, eine Funktion, die entwickelt wurde, um die Ausführung von Matrixmultiplikationen – einem Schlüsselvorgang in vielen KI-Algorithmen – zu verbessern, wodurch sie schneller und energieeffizienter wird. Die H100 bietet auch einen erheblichen Anstieg in der Speicherbandbreite und -kapazität, sodass sie größere Datensätze und komplexere neuronale Netzwerke mühelos verarbeiten kann.
NVIDIA A100 (Ampere-Architektur)
Die A100, basierend auf der früheren Ampere-Architektur von NVIDIA, brachte mehrere Innovationen mit sich, die sie weiterhin für eine Vielzahl von KI-Anwendungen relevant machen. Sie verfügt über leistungsstarke Tensor Cores der 3. Generation, die eine beschleunigte Leistung für KI-gesteuerte Aufgaben in verschiedenen Bereichen bieten, von der wissenschaftlichen Berechnung bis hin zur Datenanalyse.
Eine der herausragenden Funktionen, die die A100 eingeführt hat, ist die Multi-Instance-GPU (MIG) Fähigkeit, die es ermöglicht, die GPU in kleinere, unabhängige Instanzen zu partitionieren. Diese Vielseitigkeit macht die A100 besonders geeignet für Umgebungen, in denen mehrere Anwendungen gleichzeitig laufen müssen, ohne sich gegenseitig zu stören, was die Ausnutzung und Effizienz der GPU-Ressourcen maximiert.
Schauen wir uns an, wie sich die H100 und A100 in Bezug auf Spezifikationen und Kernarchitektur vergleichen.
Vergleich der Spezifikationen: A100 vs. H100 PCIe vs. H100 SXM5
GPU-Merkmale | NVIDIA A100 | NVIDIA H100 PCIe | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU-Board-Formfaktor | SXM4 | PCIe Gen 5 | SXM5 |
SMs | 108 | 114 | 132 |
TPCs | 54 | 57 | 66 |
FP32-Kerne / SM | 64 | 128 | 128 |
FP32-Kerne / GPU | 6912 | 14592 | 16896 |
FP64-Kerne / SM (ohne Tensor) | 32 | 64 | 64 |
FP64-Kerne / GPU (ohne Tensor) | 3456 | 7296 | 8448 |
INT32-Kerne / SM | 64 | 64 | 64 |
INT32-Kerne / GPU | 6912 | 7296 | 8448 |
Tensor-Kerne / SM | 4 | 4 | 4 |
Tensor-Kerne / GPU | 432 | 456 | 528 |
Textureinheiten | 432 | 456 | 528 |
Speicherinterface | 5120-bit HBM2 | 5120-bit HBM2e | 5120-bit HBM3 |
Speicherbandbreite | 1555 GB/s | 2000 GB/s | 3000 GB/s |
Maximale thermische Verlustleistung (TDP) | 400 Watt | 350 Watt | 700 Watt |
*Eine detailliertere Übersicht der H100- und A100-Spezifikationen anzeigen.
Wie die H100 im Vergleich zur A100 in der Kernarchitektur abschneidet
Die NVIDIA H100 GPU bringt erhebliche Fortschritte in der Kernarchitektur im Vergleich zur A100 mit zahlreichen Upgrades und neuen Funktionen, die speziell auf moderne KI- und Hochleistungsrechenanforderungen zugeschnitten sind.
Tensor Cores und Rechenleistung
Die H100 ist mit Tensor Cores der vierten Generation ausgestattet, die deutlich schneller sind als die Tensor Cores der dritten Generation in der A100. Laut NVIDIA bieten die Cores bis zu 6-fache Chip-zu-Chip-Geschwindigkeit, einschließlich einer Beschleunigung pro SM (Streaming Multiprocessor), einer erhöhten Anzahl von SMs und höheren Taktraten. Insbesondere liefern sie die doppelte Matrix-Multiply-Accumulate (MMA)-Rechenrate bei äquivalenten Datentypen und die vierfache Rate bei Verwendung des neuen FP8-Datentyps.
Neue Architekturfunktionen
DPX-Befehle:
Diese beschleunigen dynamische Programmieralgorithmen um bis zu das 7-fache im Vergleich zur A100, was Anwendungen wie Genomik-Verarbeitung und optimale Routenplanung für Roboter verbessert.
Thread Block Cluster:
Diese neue Funktion ermöglicht die programmatische Steuerung von Gruppen von Thread-Blöcken über mehrere SMs hinweg, was die Datensynchronisation und den Datenaustausch verbessert, ein bedeutender Fortschritt gegenüber den Fähigkeiten der A100.
Verteiltes gemeinsames Speicher- und asynchrones Ausführen:
Diese Funktionen ermöglichen direkte SM-zu-SM-Kommunikation und effiziente Datenübertragungen, was Verbesserungen gegenüber der Architektur der A100 darstellt.
Transformer Engine:
Diese speziell für die H100 entwickelte Engine optimiert das Training und die Inferenz von Transformator-Modellen, verwaltet Berechnungen effizienter und steigert die KI-Trainings- und Inferenzgeschwindigkeiten im Vergleich zur A100 erheblich.
Speicher- und Cache-Verbesserungen
Die H100 führt HBM3-Speicher ein, der nahezu die doppelte Bandbreite des in der A100 verwendeten HBM2 bietet. Sie verfügt auch über einen größeren 50 MB L2-Cache, der hilft, größere Teile von Modellen und Datensätzen zu cachen, wodurch die Datenabrufzeiten erheblich reduziert werden.
Interkonnektivität und Skalierbarkeit
Verbesserte NVLink- und NVSwitch-Technologien in der H100 bieten erhebliche Bandbreitensteigerungen und unterstützen umfangreichere und effizientere GPU-Clusterfähigkeiten im Vergleich zur A100. Das neue NVLink Switch-System ermöglicht auch ein umfangreicheres und isolierteres GPU-Netzwerk.
Wie man die Leistung der H100 und A100 vergleicht
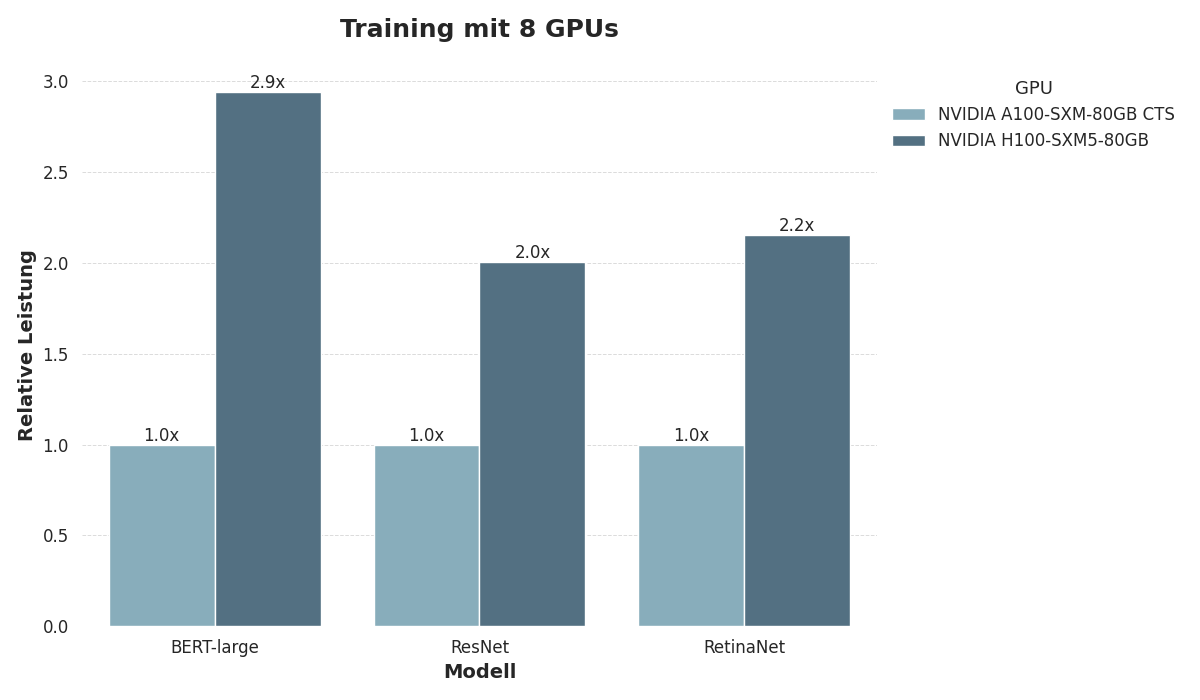
Um A100 und H100 zu vergleichen, haben wir ihre Leistung anhand der MLPerf-Training und MLPerf-Inference-Datacenter 3.0 Benchmarks für maschinelles Lernen bewertet.
Wir bewerteten die Trainingsleistung mithilfe von drei Modellen:
Das PLM BERT-Large,
Das ResNet v1.5 Vision-Modell und
Das RetinaNet Objekt-Erkennungsmodell.
Beim Training verwendeten wir Konfigurationen mit 8 GPUs, die jeweils mit 80 GB Speicher ausgestattet waren.
Wir untersuchten die Inferenzgeschwindigkeit mit vier verschiedenen Modellen:
Das PLM BERT-Large,
Das Empfehlungsmodell DLRM,
Das volumetrische Segmentierungsmodell 3D-UNet und
Das ResNet v1.5 Vision-Modell.
Beim inferenz verwendeten wir Konfigurationen mit 8 GPUs, die jeweils mit 80 GB Speicher ausgestattet waren.
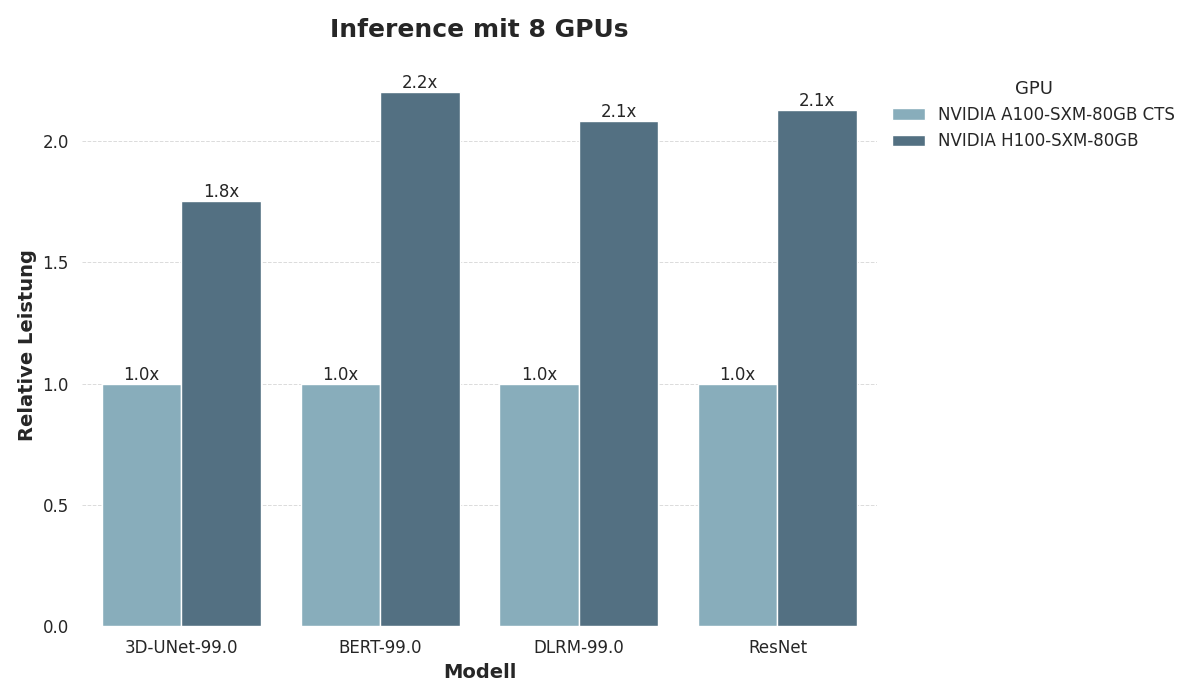
Sowohl das Training als auch die Inferenz zeigen eine erhebliche Leistungslücke zwischen A100 und H100, wobei H100 regelmäßig die doppelte Inferenz- und Trainingsgeschwindigkeit im Vergleich zu A100 liefert. Beim Training von BERT-Large verdreifacht sich die Leistung im Vergleich zu A100 sogar. Dies unterstreicht die großen Unterschiede zwischen den Hopper- und Ampere-Architekturen.
Überlegene KI-Leistung mit der H100
Die H100 ist speziell für optimale Leistung bei KI- und ML-Workloads konzipiert. Sie führt neue SMs (Streaming Multiprocessors) ein, die eine höhere Durchsatzrate und Effizienz bieten. Für KI-Entwickler bedeutet dies kürzere Modelltrainingszeiten und effizientere Inferenzberechnungen, insbesondere bei den anspruchsvollsten KI-Modellen.
Vielseitigkeit und Beständigkeit mit der A100
Während die A100 möglicherweise nicht mit den rohen KI-spezifischen Verbesserungen der H100 mithalten kann, macht ihre robuste Leistung über verschiedene Rechenaufgaben hinweg sie zu einer zuverlässigen Wahl für viele Entwickler. Die Fähigkeit der A100, verschiedene Präzisionsformate (FP32, FP64 usw.) mit hoher Effizienz zu verarbeiten, stellt sicher, dass sie eine Spitzenkandidatin für Aufgaben bleibt, die eine Balance von Genauigkeit und Geschwindigkeit erfordern.
Spitzenleistung | NVIDIA A100 | NVIDIA H100 PCIe | NVIDIA H100 SXM5 |
|---|---|---|---|
Spitzen-FP16-Tensor-TFLOPS mit FP16 Akkumulation* | 312/624* | 800/1600* | 1000/2000* |
Spitzen-FP16-Tensor-TFLOPS mit FP32 Akkumulation* | 312/624* | 800/1600* | 1000/2000* |
Spitzen-BF16-Tensor-TFLOPS mit FP32 Akkumulation* | 312/624* | 800/1600* | 1000/2000* |
Spitzen-TF32-Tensor-TFLOPS* | 156/312* | 400/800* | 500/1000* |
Spitzen-FP64-Tensor-TFLOPS* | 19.5 | 48 | 60 |
Spitzen-INT8-Tensor-TOPS* | 624/1248* | 1600/3200* | 2000/4000* |
Spitzen-FP16-TFLOPS (ohne Tensor)* | 78 | 96 | 120 |
Spitzen-BF16-TFLOPS (ohne Tensor)* | 39 | 96 | 120 |
Spitzen-FP32-TFLOPS (ohne Tensor)* | 19.5 | 48 | 60 |
Spitzen-FP64-TFLOPS (ohne Tensor)* | 9.7 | 24 | 30 |
Spitzen-INT32-TOPS* | 19.5 | 24 | 30 |
*mit Sparsität
Kostenvergleich von H100 und A100
Wenn Sie die Kosten der NVIDIA H100 und A100 vergleichen, ist es wichtig zu beachten, dass es sich bei beiden um Premium-Cloud-GPUs handelt, die für anspruchsvolle KI-Workloads entwickelt wurden. Die Verfügbarkeit beider GPUs für den Verbrauchermarkt ist begrenzt, und die beste Option ist, einen Cloud-GPU-Plattformanbieter wie DataCrunch zu nutzen.
Aktuelle On-Demand-Preise der NVIDIA H100 und A100:*
Kosten der H100 SXM5: $2,65/Stunde.
Kosten der A100 SXM4 80GB: $1,65/Stunde.
Kosten der A100 SXM4 40GB: $1,29/Stunde.
*Siehe Echtzeitpreise der A100 und H100.
Wenn Sie die Preise der A100 bewerten, ist es wichtig, auf die Menge des GPU-Speichers zu achten. Im Fall der A100 gibt es sowohl 40GB- als auch 80GB-Optionen, und die kleinere Option ist möglicherweise nicht für die größten Modelle und Datensätze geeignet.
Ein weiterer Faktor, der den Kostenvergleich zwischen H100 und A100 erschwert, ist, dass beide GPUs in verschiedenen Formfaktoren angeboten werden: SXM und PCIe. Für anspruchsvolle KI-Workloads bietet der SXM-Formfaktor deutliche Vorteile.
Die Wahl treffen: H100 oder A100?
Die Entscheidung zwischen der H100 und der A100 hängt weitgehend von den spezifischen Projektanforderungen ab:
Für KI-Tests, Training und Inferenz, die die neueste GPU-Technologie und spezialisierte KI-Optimierungen erfordern, kann die H100 die bessere Wahl sein. Ihre Architektur ist in der Lage, die höchsten Rechenbelastungen zu bewältigen und ist zukunftssicher, um die nächste Generation von KI-Modellen und -Algorithmen zu handhaben.
Für gemischte Workloads und Umgebungen, in denen Kosteneffizienz, Vielseitigkeit und eine robuste Leistung über eine Vielzahl von Anwendungen hinweg geschätzt werden, bleibt die A100 eine gute Option. Ihre MIG-Fähigkeiten und breite Anwendbarkeit machen sie ideal für Rechenzentren und Unternehmen mit unterschiedlichen Rechenanforderungen.
Die GPUs NVIDIA H100 und A100 bieten beide leistungsstarke Optionen für KI-Entwickler, aber die beste Wahl hängt von den spezifischen Anforderungen Ihrer Projekte ab. Bei DataCrunch bieten wir sowohl die H100 SXM5 als auch die A100 SXM4 On-Demand an. Starten Sie eine Instanz und probieren Sie es selbst aus.