
Laut den meisten Benchmarks ist die NVIDIA H100 derzeit die beste GPU für KI-Training und Inferenz. Während neue Konkurrenten wie die GB200 bereits am Horizont erscheinen, steht der nächste große Leistungssprung bei GPUs kurz bevor. Die NVIDIA H200 wird noch vor Ende 2024 auf Premium-Cloud-GPU-Plattformen wie DataCrunch verfügbar sein.
In diesem Artikel vergleichen wir die GPU-Architekturen, Schlüsselmerkmale, Benchmark-Ergebnisse und Preisüberlegungen der H200 und H100, um Ihnen bei der Wahl der besten GPU für Ihre kommenden KI-Workloads zu helfen.
Was ist die H200?
Die NVIDIA H200 ist eine Tensor-Core-GPU, die speziell für den Einsatz in Hochleistungsrechnern und KI-Anwendungsfällen entwickelt wurde. Sie basiert auf der Hopper-GPU-Architektur und ist darauf ausgelegt, maximale Leistung im parallelen Rechnen zu erreichen.

NVIDIA stellte die H200 im November 2023 als direkte Verbesserung zur H100 vor, die bessere Leistung, Effizienz und Skalierbarkeit verspricht. Mit 141 Gigabyte (GB) HBM3e-Speicher bei 4,8 Terabyte pro Sekunde (TB/s) verdoppelt sie nahezu die Kapazität der NVIDIA H100 bei zentralen KI-Workloads wie LLM-Inferenz.
Bis neue GPUs der Blackwell-Serie breiter auf dem Markt verfügbar sind, wird die H200 voraussichtlich die schnellste und kosteneffizienteste GPU für die anspruchsvollsten KI-Workloads sein. Sie wird auch mit deutlich geringeren Gesamtbetriebskosten (TCO) als die H100 einhergehen.
H200 vs. H100 Spezifikationsvergleich
Technische Spezifikationen | H100 SXM | H200 SXM |
|---|---|---|
Formfaktor | SXM5 | SXM5 |
FP64 | 34 TFLOPS | 34 TFLOPS |
FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
FP32 | 67 TFLOPS | 67 TFLOPS |
TF32 Tensor Core* | 989 TFLOPS | 989 TFLOPS |
BFLOAT16 Tensor Core* | 1.979 TFLOPS | 1.979 TFLOPS |
FP16 Tensor Core* | 1.979 TFLOPS | 1.979 TFLOPS |
FP8 Tensor Core* | 3.958 TFLOPS | 3.958 TFLOPS |
INT8 Tensor Core* | 3.958 TFLOPS | 3.958 TFLOPS |
GPU-Speicher | 80 GB | 141 GB |
Speicherbandbreite der GPU | 3,35 TB/s | 4,8 TB/s |
Maximaler TDP (Thermal Design Power) | Bis zu 700W (konfigurierbar) | Bis zu 700W (konfigurierbar) |
Multi-Instance GPUs | Bis zu 7 MIGs @10GB pro Einheit | Bis zu 7 MIGs @16,5GB pro Einheit |
Interconnect | NVIDIA NVLink®: 900GB/s | PCIe Gen5: 128GB/s <br> NVIDIA <br> NVLink®: 900GB/s. <br> PCIe Gen5: 128GB/s | |
Die H200 wird voraussichtlich eine verbesserte Version der H100 sein und ein ähnliches Spektrum an Rechenfähigkeiten (von FP64 bis INT8) beibehalten. Unter der Haube teilen sich die H100 und H200 viele der gleichen Komponenten, Netzwerkkonfigurationen und architektonischen Entscheidungen.
Der wichtigste Unterschied liegt im massiven Anstieg des VRAM, wobei die 141 GB HBM3e-Speicher ein erhebliches Upgrade gegenüber den 80 GB HBM3 der H100 darstellen.
Die H200 bietet 43 % mehr Speicherbandbreite als die H100, mit einem Maximum von 4,8 TB/s und 900 GB/s P2P-Bandbreite.
Vergleich von H200 und H100 bei KI-Workloads
Der größere und schnellere Speicher der H200 wird einen erheblichen Einfluss auf zentrale KI-Workloads haben. Die H200 erhöht die Inferenzgeschwindigkeit im Vergleich zu H100-GPUs bei LLMs wie Llama2 70B um bis zu das Doppelte.
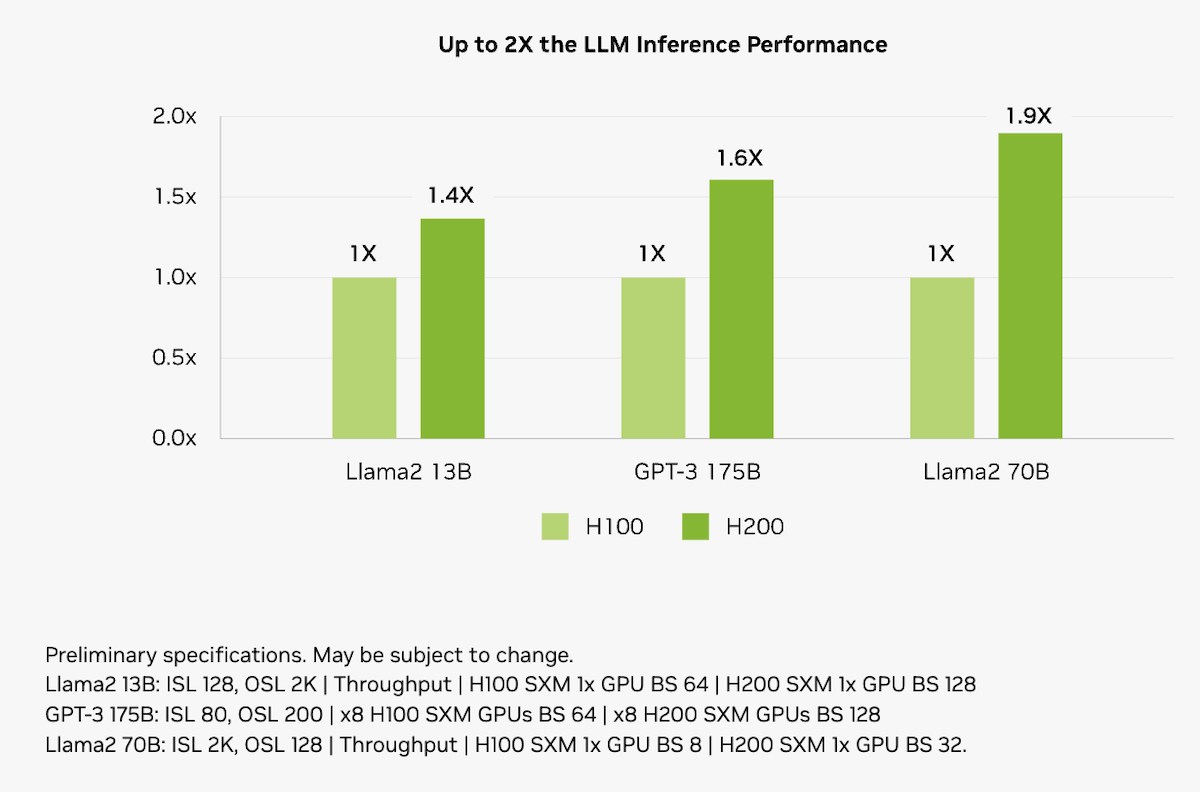
H200 vs H100 AI inference comparison. Source:nvidia.com
The H200 also delivers impressive gains in AI training throughput. On the new graph neural network (GNN) test based on R-GAT, the H200 delivered a 47% boost on single-node GNN training compared to the H100.
Thermal Design Power (TDP)
One of the major points of criticism for the H100 was in system power consumption. NVIDIA addresses this concern with a far better cost-efficiency over the lifetime of a GPU.
The H200 achieves performance improvements while maintaining the same 700W power profile as the H100. While this doesn’t sound like an upgrade, the expected performance-per-watt for computing power will be significantly better.
H200 vs H100 KI-Inferenzvergleich. Quelle: nvidia.com
Die H200 bietet auch beeindruckende Verbesserungen in der KI-Training-Durchsatzrate. Im neuen Test der Graph-Neural-Networks (GNN) basierend auf R-GAT lieferte die H200 einen 47% höheren Durchsatz beim GNN-Training auf einem einzelnen Knoten im Vergleich zur H100.
Thermal Design Power (TDP)
Einer der Hauptkritikpunkte an der H100 war der Stromverbrauch des Systems. NVIDIA geht dieses Problem mit einer wesentlich besseren Kosteneffizienz über die Lebensdauer einer GPU an.
Die H200 erzielt Leistungsverbesserungen und behält dabei das gleiche 700W-Leistungsprofil wie die H100 bei. Auch wenn dies nicht wie ein Upgrade klingt, wird die erwartete Leistung pro Watt für Rechenleistung deutlich besser sein.
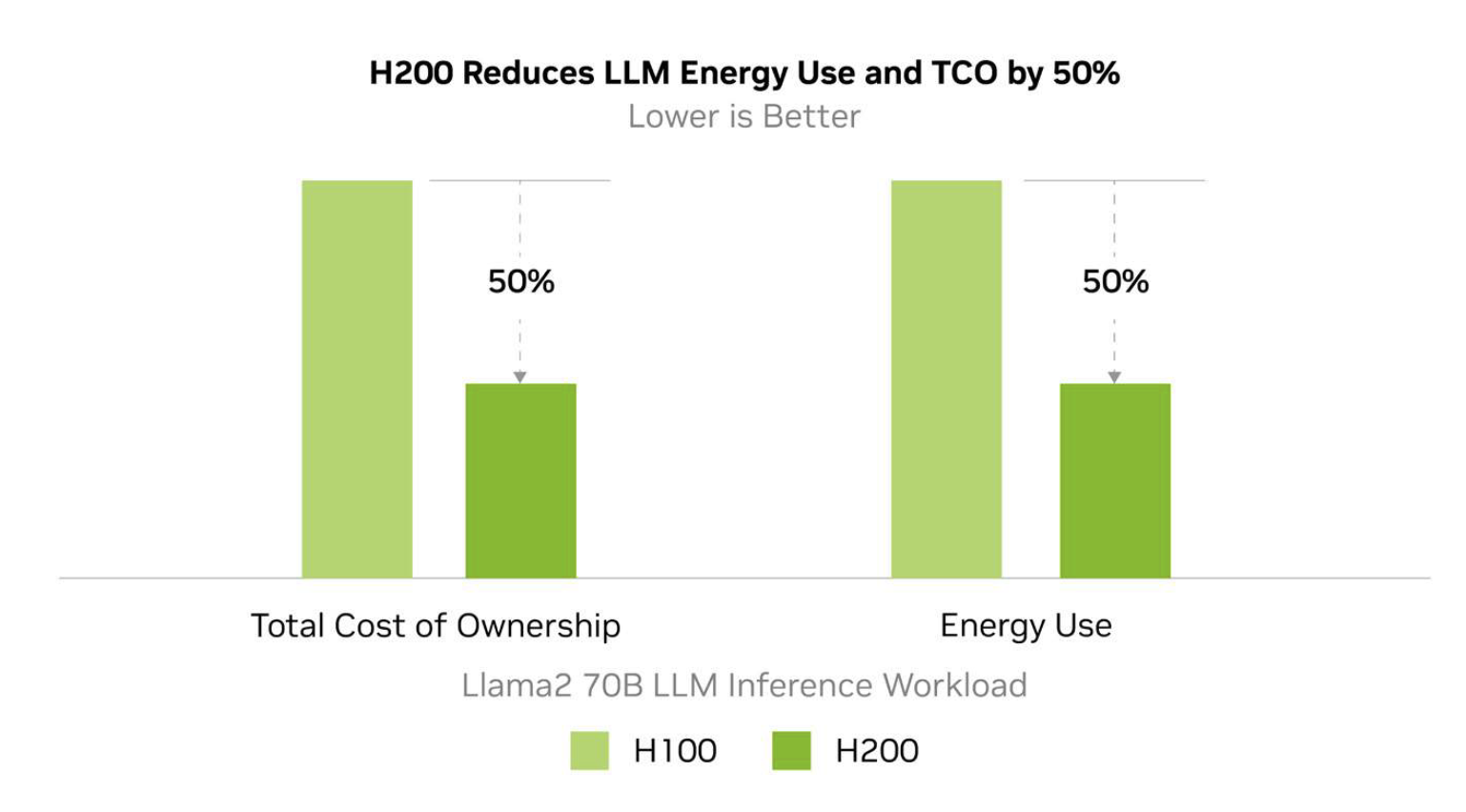
Vergleich der Gesamtbetriebskosten (TCO) von H200 und H100. Quelle: nvidia.com
NVIDIA schätzt, dass der Energieverbrauch der H200 bei wichtigen LLM-Inferenz-Workloads bis zu 50 % niedriger sein wird als bei der H100, was zu 50 % geringeren Gesamtbetriebskosten über die Lebensdauer des Geräts führt.
Vergleich von H200 und H100 HGX-Systemen
Da der Bedarf an KI-Training mit immer größeren Sprachmodellen steigt, überschreiten die Rechenlimits die einer einzelnen GPU-Architektur. NVIDIA begegnet dieser Herausforderung mit der HGX-KI-Supercomputing-Plattform.

H200 HGX-System mit *NVLink Switch-Chips. Quelle: nvidia.com
Das HGX integriert bis zu 8 H200-GPUs mit Hochgeschwindigkeits-NVLink-Verbindungen und optimierten Software-Stacks, darunter CUDA, Magnum IO und Doca. HGX bietet eine vielseitige Plattform, die von einzelnen Systemen bis hin zu großen Rechenzentrums-Clustern skalierbar ist.
Vergleich der HGX H100 und H200 8-GPU-Systeme
Merkmal | HGX H100 8-GPU | HGX H200 8-GPU |
|---|---|---|
FP8 TFLOPS | 32.000 | 32.000 |
FP16 TFLOPS | 16.000 | 16.000 |
GPU-zu-GPU Bandbreite | 900GB/s | 900GB/s |
Quantum-2 InfiniBand-Netzwerk | 400GB/s | 400GB/s |
Gesamte Bandbreite | 3,6TB/s | 7,2TB/s |
Speicher | 640GB HBM | 1,1TB HBM3e |
NVLink | Vierte Generation | Vierte Generation |
GPU Gesamt-Bandbreite | 27GB/s | 38GB/s |
Architektonisch teilen die HGX-Systeme H100 und H200 viele der gleichen Designentscheidungen, aber die H200 bietet eine 2-fache Erhöhung der gesamten Bandbreite und einen 72% Anstieg des verfügbaren Gesamtspeichers.
Kosten der H100 und H200
Weder die H100 noch die H200 sind GPUs, die man einfach im Laden kaufen kann. Die Kosten für eine einzelne GPU oder ein HGX-System hängen von Ihrer Konfiguration und den Lieferoptionen ab.
Wir können erwarten, dass die H200 etwa 20 % mehr pro Stunde kostet, wenn sie als virtuelle Maschineninstanz bei Cloud-Service-Anbietern genutzt wird.
Stundentarife für die H100 und H200 auf der DataCrunch Cloud-Plattform:
H100 SXM5 | H200 SXM5 | |
|---|---|---|
Preis auf Abruf /Stunde | 3,35 $ | 4,02 $ |
2-Jahres-Vertrag /Stunde | 2,51 $ | 3,62 $ |
Auswirkungen in der Praxis
In den letzten Jahren hat die Nachfrage nach NVIDIAs Rechenzentrums-GPUs wie der H100 das Angebot bei Weitem übertroffen, was zu einem Wettlauf um begrenzte Rechenressourcen zwischen großen Tech-Konzernen und neuen KI-Startups geführt hat.
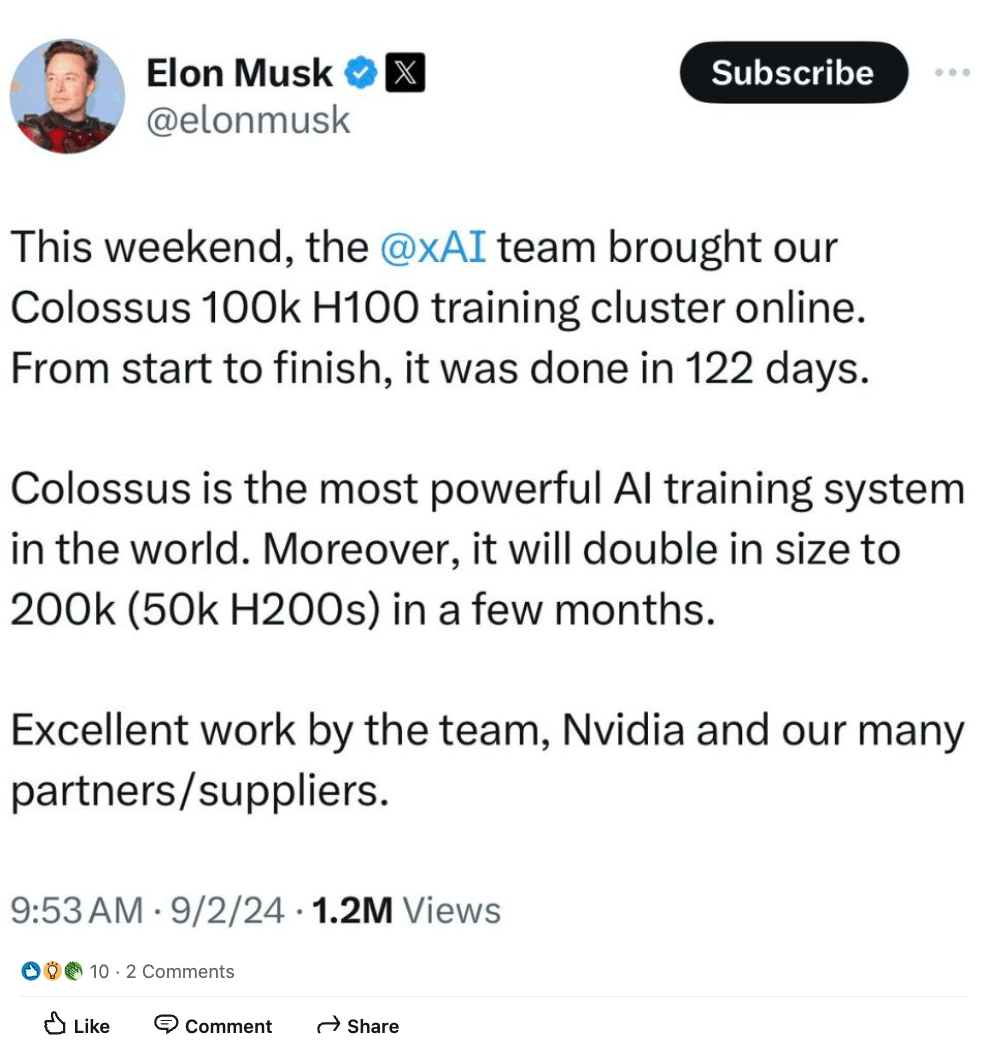
Während sich die Verfügbarkeit der H100 im Jahr 2024 verbessert hat, bleibt das Interesse an H100 und H200 weiterhin hoch. Um Ihnen eine Vorstellung von der Größenordnung zu geben: Elon Musk hat kürzlich die Aktivierung eines 100.000 H100 Trainingsclusters für xAI angekündigt, mit Plänen, innerhalb weniger Monate zusätzlich 50.000 H200s hinzuzufügen.
Fazit zum Vergleich zwischen H200 und H100
Während wir auf den vollständigen Rollout von Systemen der nächsten Generation wie der GB200 warten, werden sowohl die H100 als auch die H200 in den kommenden Jahren die Grenzen der KI-Entwicklung herausfordern.
Da KI-Modelle weiter an Größe zunehmen, wird der Bedarf an Rechengeschwindigkeit und Effizienz steigen. Die H200 wird eine großartige Option sein, sobald sie verfügbar ist. Bis dahin bleibt die H100 Ihre beste Wahl. Starten Sie noch heute eine Instanz auf der DataCrunch Cloud-Plattform!