
If you’re an AI engineer, you’re likely already familiar with the H100 based on the information provided by NVIDIA. Let’s go a step beyond and review what the H100 GPU specs and price mean for machine learning training and inference.
A completely new GPU architecture
The “H” in H100 stands for Hopper architecture in respect to Grace Hopper, the famed computer scientist. This is a completely new GPU architecture specifically designed with a strong focus on accelerating cloud-based AI computations.
The Hopper architecture introduces significant improvements, including 4th generation Tensor Cores optimized for AI, especially for tasks involving deep learning and large language models.
H100 SXM vs PCIe
As with previous NVIDIA high-performance GPUs the H100 is available in two main form factors, the SXM5 and the PCIe. Between the two there are substantial differences in performance.
H100 SXM5
The SXM5 configuration is designed for maximum performance and multi-GPU scaling. It features the highest SM count, faster memory bandwidth, and superior power delivery compared to the PCIe version. The SXM5 is ideal for demanding AI training and HPC workloads that require the highest possible performance.
H100 PCIe Gen 5
The PCIe Gen 5 configuration is a more mainstream option, offering a balance of performance and efficiency. It has a lower SM count and reduced power requirements compared to the SXM5. The PCIe version is suitable for a wide range of data analytics and general-purpose GPU computing workloads.
H100 data sheet comparison of SXM vs PCIe
Specification | H100 SXM | H100 PCIe |
|---|---|---|
FP64 | 34 TFLOPS | 26 TFLOPS |
FP64 Tensor Core | 67 TFLOPS | 51 TFLOPS |
FP32 | 67 TFLOPS | 51 TFLOPS |
TF32 Tensor Core | 989 TFLOPS | 756 TFLOPS |
BFLOAT16 Tensor Core | 1,979 TFLOPS | 1,513 TFLOPS |
FP16 Tensor Core | 1,979 TFLOPS | 1,513 TFLOPS |
FP8 Tensor Core | 3,958 TFLOPS | 3,026 TFLOPS |
INT8 Tensor Core | 3,958 TOPS | 3,026 TOPS |
GPU memory | 80GB | 80GB |
GPU memory bandwidth | 3.35TB/s | 2TB/s |
Max thermal design power (TDP) | Up to 700W | 300-350W |
Form factor | SXM | PCIe dual-slot |
Interconnect | NVLink: 900GB/s | NVLink: 600GB/s |
MLPerf Benchmark performance
We evaluated the inference performance of PCIe and SXM5 on the MLPerf machine learning benchmark, focusing on two popular tasks:
LLM inference using the Llama 2 70B LoRA model, and
Image generation using Stable Diffusion XL.
For both tasks, we used configurations with 8 GPUs, each equipped with 80 GB of memory.
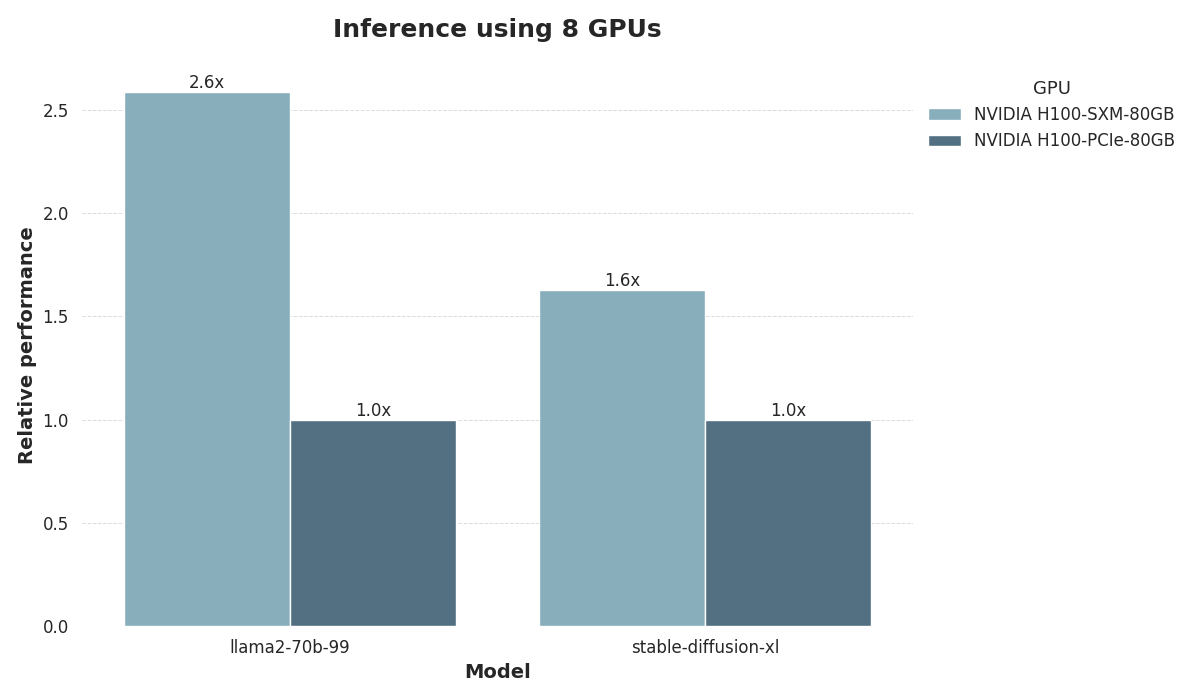
The results clearly demonstrate the advantages of the SXM5 form factor. SXM5 delivers a striking 2.6x speedup in LLM inference compared to PCIe. For image generation, the SXM5 still outperforms PCIe by 1.6x, though the performance gap is less pronounced. These findings underscore the SXM5’s significant edge over PCIe, particularly with large modern deep learning models.
Developer tools for H100
As you can expect, NVIDIA provides a full suite of developer tools to help optimize, debug, and deploy applications on the H100. These tools include the NVIDIA Visual Profiler, NVIDIA Nsight Systems, and NVIDIA Nsight Compute, which enable developers to analyze and improve application performance.
Additionally, the NVIDIA GPU Cloud (NGC) provides a catalog of pre-optimized software containers, models, and industry-specific SDKs, simplifying the deployment of AI and HPC workloads on H100-powered systems.
CUDA platform and programming model
The H100 is supported by the latest version of the CUDA platform, which includes various improvements and new features. The updated programming model introduces Thread Block Clusters, which enable efficient data sharing and communication between thread blocks, improving performance on certain types of workloads.
Frameworks, libraries, and SDKs
NVIDIA offers a wide range of GPU-accelerated libraries, frameworks, and SDKs that are optimized for the H100. These include popular deep learning frameworks such as TensorFlow and PyTorch, as well as high-performance libraries like cuDNN, cuBLAS, and NCCL. The H100 also benefits from domain-specific SDKs, such as NVIDIA Clara for healthcare and NVIDIA Morpheus for cybersecurity.
H100 impact on MMA
The NVIDIA H100 GPU introduces several enhancements that significantly improve the performance of matrix multiply and accumulate (MMA) operations:
Fourth-generation Tensor Cores: The H100 features enhanced Tensor Cores that provide higher peak performance for FP16, BF16, and the new FP8 data types compared to the previous generation A100 GPU. These Tensor Cores are optimized for MMA operations, enabling faster execution of these critical math functions in AI and HPC workloads.
FP8 precision: The H100 introduces the new FP8 data format, which offers 4x the compute throughput of FP16 on the A100. By using FP8 precision for MMA operations, the H100 can process more data in parallel, resulting in higher overall performance.
Transformer Engine: The H100 includes a new Transformer Engine that optimizes both hardware and software for transformer-based models. The Transformer Engine dynamically chooses between FP8 and FP16 calculations and handles re-casting and scaling between the two formats, ensuring optimal performance for MMA operations in these models.
These architectural improvements in the H100 GPU enable faster and more efficient execution of MMA operations, leading to significant performance gains in AI training, inference, and HPC workloads that heavily rely on these math functions.
Compare H100 to A100
The H100 is most naturally compared to the A100, NVIDIA’s previous high-performance GPU. Between the two there are many clear differences.
Streaming Multiprocessor (SM) improvements
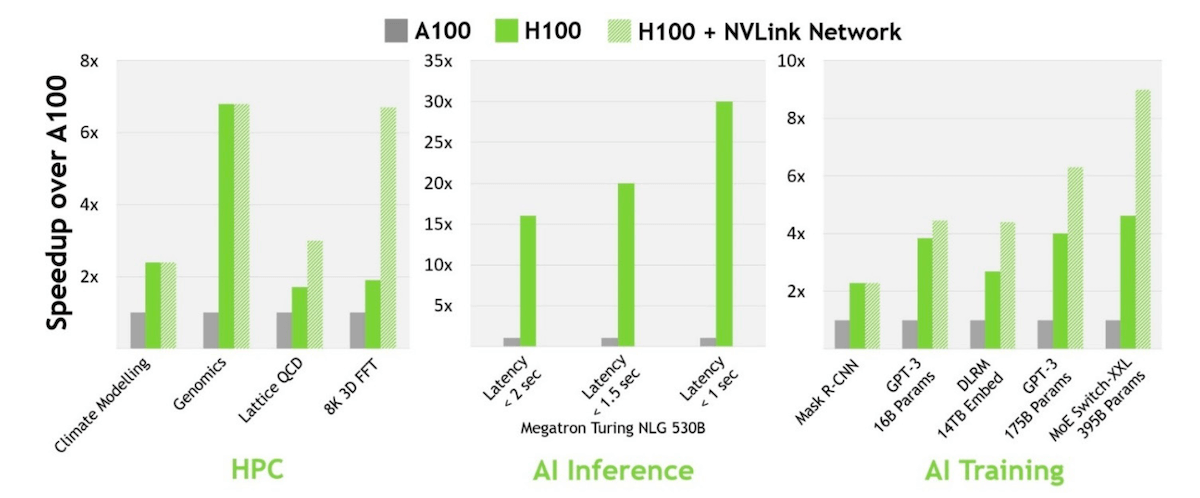
The H100 features an enhanced SM architecture with fourth-generation Tensor Cores. On a per-SM basis, the new Tensor Cores provide 2x the peak performance for FP16 and BF16 data types compared to the A100. Additionally, the H100 introduces the new FP8 data format, offering 4x the compute throughput of FP16 on the A100.
FP8 and Transformer Engine
The combination of FP8 precision and the Transformer Engine, which optimizes both hardware and software for transformer-based models, enables the H100 to achieve up to 9x higher performance compared to the A100 on AI training and 30x faster inference workloads. The Transformer Engine dynamically chooses between FP8 and FP16 calculations and handles re-casting and scaling between the two formats.
HBM3 Memory Subsystem
The H100 is the first GPU to feature HBM3 memory, delivering nearly 2x the bandwidth of the A100's HBM2e memory. With 3 TB/s of memory bandwidth, the H100 can efficiently feed data to its high-performance Tensor Cores and SMs.
Multi-Instance GPU (MIG) Enhancements
Second-generation MIG technology in the H100 provides approximately 3x more compute capacity and nearly 2x more memory bandwidth per GPU instance compared to the A100. The H100 supports up to seven MIG instances, each with dedicated NVDEC and NVJPG units, performance monitors, and support for Confidential Computing.
*For more details, see H100 vs A100 Comparison and H100 vs H200 Comparison.
How much does the NVIDIA H100 cost?
The NVIDIA H100 is a premium solution that you don’t simply buy off the shelf. When H100’s are available, they are often delivered through dedicated cloud GPU providers like DataCrunch.
The price per hour of H100 can vary greatly, especially between the high-end SXM5 and more generalist PCIe form factors. Here are the current* best available prices for the H100 SXM5:
Cost of H100 SXM5 On-demand: $2.65/hour.
Cost of H100 SXM5 with 2 year contract: $2.38/hour.
* see real-time price of A100 and H100.
When you’re deploying an H100 you need to balance out your need for compute power and the scope of your project. For training larger models or with extremely large data sets you may want to reach out to get a quote for a dedicated H100 cluster.
Bottom line on the H100 GPU
The NVIDIA H100 Tensor Core GPU, with over 80 billion transistors, is one of the most advanced chips available for intense AI workloads.
The H100 GPU is available in multiple configurations, including the SXM5 and PCIe form factors, allowing you to choose the right setup for your specific needs. In addition, you can take advantage of a number of new software solutions aimed at getting the most out of the H100s immense compute capacity.
As the demand for accelerated computing continues to grow, the NVIDIA H100 Tensor Core GPU has already proven its capacity to deliver exceptional performance, scalability and speed. This also means that there is limited availability for the H100 in the general market. If you’re looking to deploy H100 for your ML or inference projects, your best option is to work with an an authorized Nvidia partner like DataCrunch.