
It feels like a long time since NVIDIA revealed the H200 GPU back in November 2023. Since then, we’ve already learned about AMD’s MI300X and the upcoming Blackwell architecture. Not to mention, NVIDIA stock price has gone through the roof!
Let’s go through what you can get from the H200 – and most importantly what we can expect from that massive increase to VRAM and memory bandwidth in terms of machine learning training and inference use cases.
What is the NVIDIA H200
The NVIDIA H200 is a Tensor Core GPU specifically designed to be used in high performance computing and AI use-cases. It’s based on the Hopper-architecture which was itself was released in the second half of 2022.
The H200 builds upon the success of NVIDIA's previous flagship GPU, the H100, by introducing significant advancements in memory capacity, bandwidth, and energy use performance. These improvements position the H200 as the market-leading GPU for generative AI, large language models, and memory-intensive HPC applications.
Full H200 vs H100 Specs Comparison
Technical Specifications | H100 SXM | H200 SXM |
|---|---|---|
Form Factor | SXM5 | SXM5 |
FP64 | 34 TFLOPS | 34 TFLOPS |
FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
FP32 | 67 TFLOPS | 67 TFLOPS |
TF32 Tensor Core* | 989 TFLOPS | 989 TFLOPS |
BFLOAT16 Tensor Core* | 1,979 TFLOPS | 1,979 TFLOPS |
FP16 Tensor Core* | 1,979 TFLOPS | 1,979 TFLOPS |
FP8 Tensor Core* | 3,958 TFLOPS | 3,958 TFLOPS |
INT8 Tensor Core* | 3,958 TFLOPS | 3,958 TFLOPS |
GPU Memory | 80 GB | 141 GB |
GPU Memory Bandwidth | 3.35 TB/s | 4.8 TB/s |
Max Thermal Design Power (TDP) | Up to 700W (configurable) | Up to 700W (configurable) |
Multi-Instance GPUs | Up to 7 MIGs @10GB each | Up to 7 MIGs @16.5GB each |
Interconnect | - NVIDIA NVLink®: 900GB/s - PCIe Gen5: 128GB/s | - NVIDIA NVLink®: 900GB/s - PCIe Gen5: 128GB/s |
* With sparsity.
Overall, the H200 is expected to be an upgraded version of the H100 specs retaining a similar range of computational capabilities (FP64 to INT8) with a much faster and more efficient performance due to the VRAM upgrades. While the H200 is going to be a solid option, the new GB200 NVL72 is going to be the top datacenter-grade GPU from NVIDIA in years to come.
Memory and Bandwidth Upgrade
At the heart of the H200's performance is its 141GB of HBM3e (High-Bandwidth Memory) which is delivered at 4.8TB/s of memory bandwidth. In comparison, the previous-generation H100 GPU featured 80GB of HBM3 memory with a respectable 3.3TB/s of bandwidth.
Updated Benchmark Performance
Recent benchmarks highlight the H200's impressive capabilities:
Llama2-13B Model Inference: The H200 achieves approximately 11,819 tokens per second on the Llama2-13B model, marking a 1.9x performance increase over the H100.
Llama2-70B Model Inference: For the Llama2-70B model, the H200 delivers up to 3,014 tokens per second, showcasing its capability to handle larger models with remarkable efficiency.
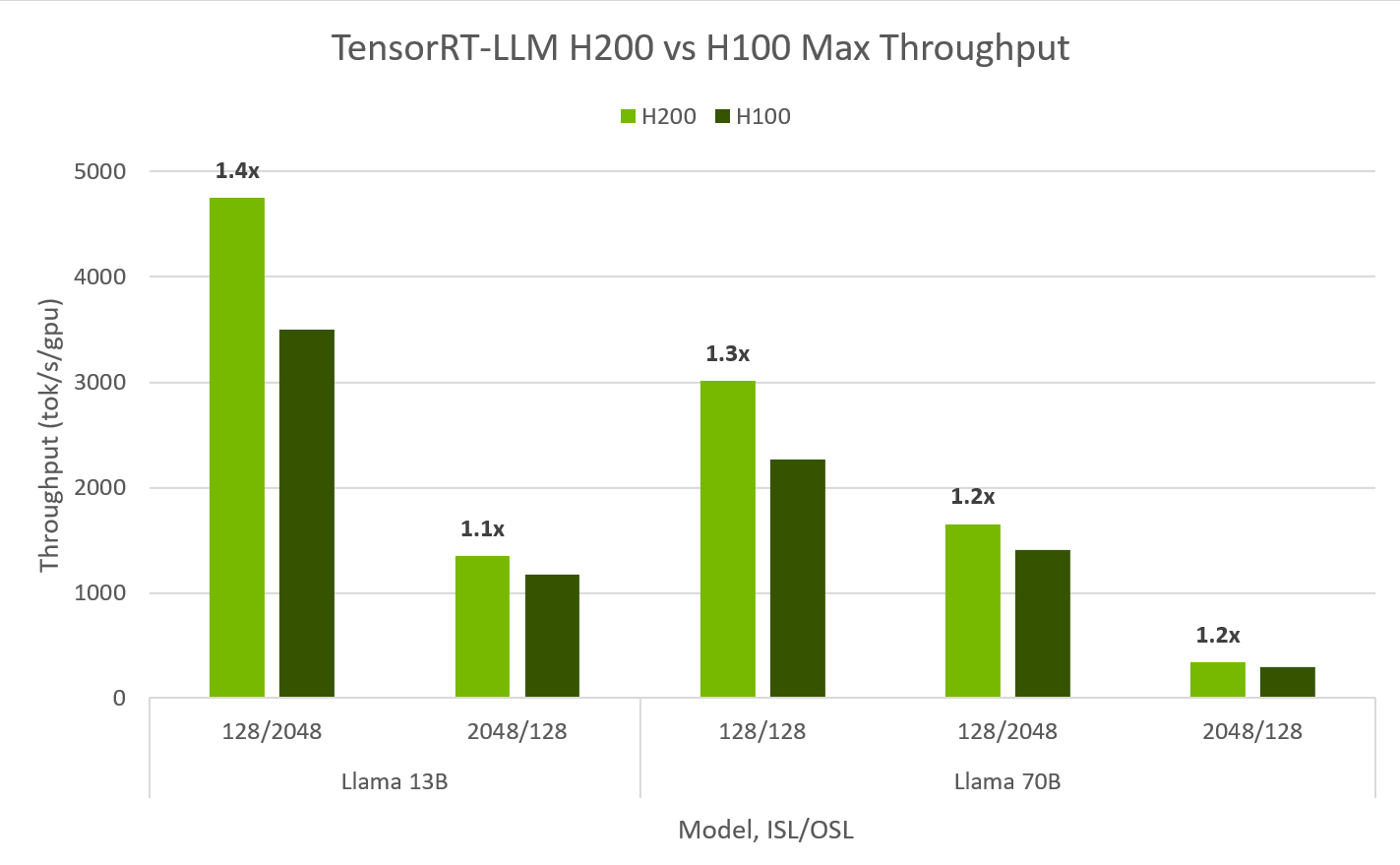
These benchmarks underscore the H200’s enhanced memory and bandwidth, facilitating faster and more efficient inference for large language models.
Beyond LLM inference, the H200 also delivers impressive gains in other AI domains, such as generative AI and training throughput. On the new graph neural network (GNN) test based on R-GAT, the H200 delivered a 47% boost on single-node GNN training compared to the H100.
Impact on Thermal Design Power (TDP)
The H200 achieves performance improvements while maintaining the same power profile as the H100. While this doesn’t sound like an upgrade, the expected performance-per-watt for computing power will be significantly better.
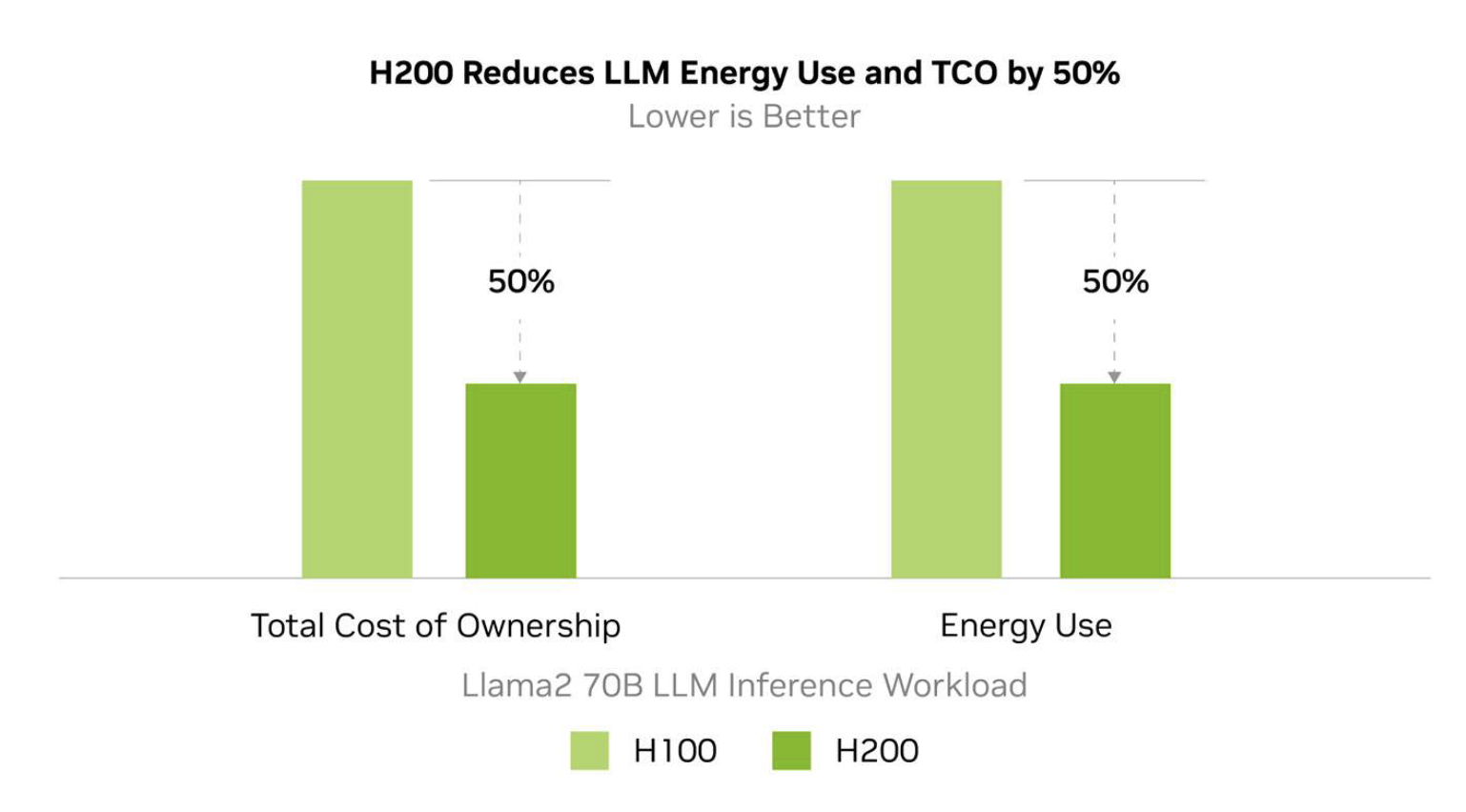
NVIDIA estimates that the energy use of the H200 will be up to 50% lower than the H100 for key LLM inference workloads, resulting in a 50% lower total cost of ownership over the lifetime of the device.
The GH200 Superchip: Related but Different
In addition to the H200, NVIDIA has also introduced the GH200 Grace Hopper Superchip. While related, the GH200 is not the same as the H200. The GH200 combines an NVIDIA Hopper GPU (similar to the H200) with the Grace CPU, creating a unified platform that provides a massive boost in performance for complex AI and HPC workloads.
The GH200 is designed specifically for scenarios that require tightly integrated CPU and GPU resources, enabling high-speed data sharing between the Grace CPU and the Hopper GPU through NVIDIA’s NVLink-C2C interconnect. This setup results in an accelerated workflow for applications such as large-scale AI model training, data analytics, and scientific simulations.
Key differences between the GH200 and H200 include:
CPU Integration: The GH200 integrates the Grace CPU alongside the Hopper GPU, providing a heterogeneous computing platform. In contrast, the H200 is a standalone GPU.
Memory Capacity: The GH200 features up to 480GB of HBM3e, compared to the 141GB in the H200, making it more suitable for extremely large datasets.
Target Use Cases: The GH200 is ideal for workloads requiring seamless CPU-GPU coordination, such as large-scale AI training, while the H200 is optimized for pure GPU compute tasks.
While both are based on the Hopper architecture and deliver exceptional performance, the GH200 and H200 serve different purposes. The H200 excels in GPU-centric tasks, while the GH200 is tailored for applications that demand a high degree of CPU-GPU collaboration.
H200 GPU Pricing on DataCrunch: Fixed vs. Dynamic Pricing
DataCrunch offers two distinct pricing options for H200 GPU instances: Fixed Pricing and Dynamic Pricing. This flexibility allows you to choose the best pricing model to fit your workload and budget needs.
Fixed Pricing: The fixed price for H200 GPU instances is currently $3.59 per hour. This rate guarantees predictable costs, making it an ideal option for projects that require consistent budgeting and planning. With fixed pricing, you lock in the rate and avoid fluctuations, ensuring stability.
Dynamic Pricing: Alternatively, DataCrunch provides a Dynamic Pricing model, currently starting at $2.62 per hour. Dynamic pricing changes based on real-time supply and demand for GPU resources. This means you could potentially benefit from lower rates during off-peak periods. While this pricing model offers the chance for cost savings, it also comes with the variability of pricing that might fluctuate as demand for GPU resources changes.
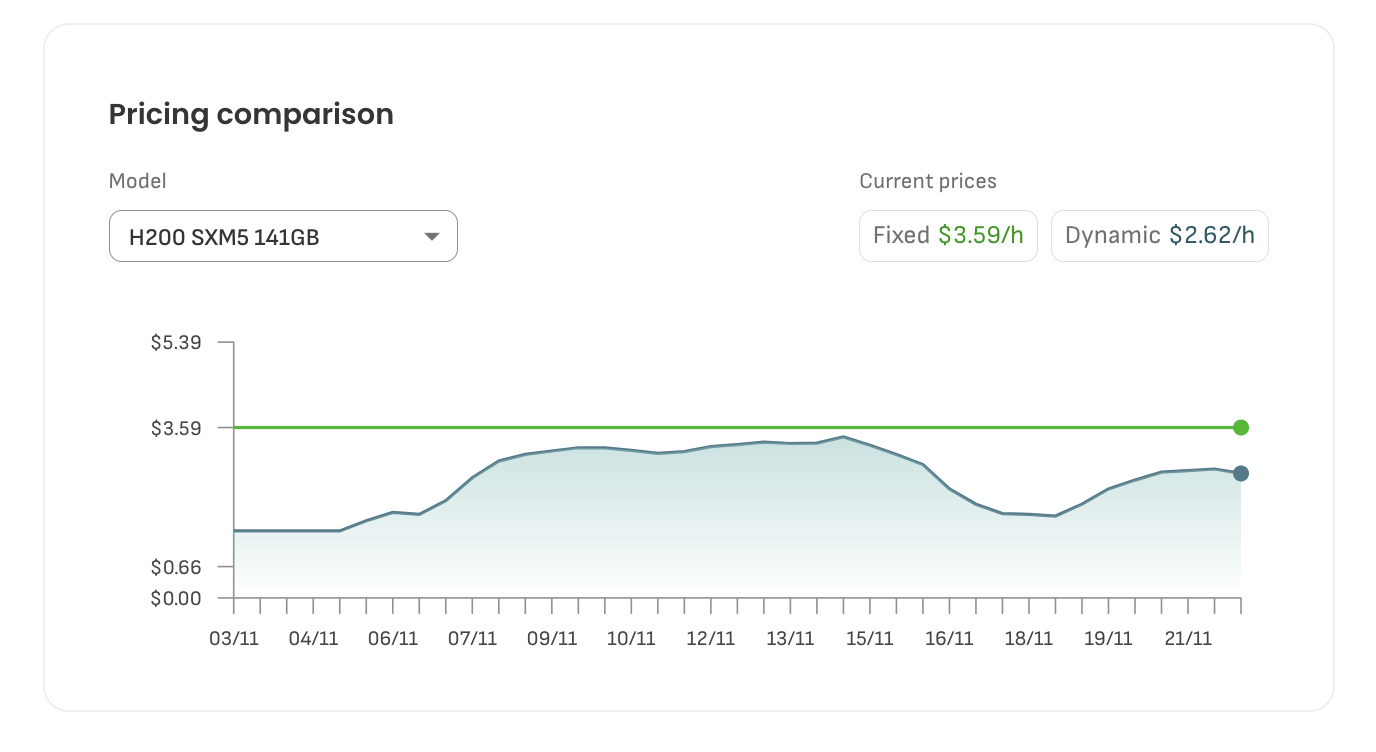
The chart above shows recent price trends for H200 GPU instances on the DataCrunch platform. The dynamic pricing fluctuates daily, influenced by factors such as GPU availability and market demand. If you are flexible about the timing of your workloads, the dynamic pricing model can lead to substantial cost reductions compared to the fixed price.
Overall, DataCrunch's pricing flexibility ensures that whether you prefer predictable costs or are open to optimizing for lower rates, you have the choice that best fits your project's financial and operational requirements.
Deploy H200s today with DataCrunch
If you feel like a kid waiting for Christmas, you’re not alone. The H200 has ideal specifications to advance machine learning and high-performance computing to new levels, and it’s going to be some time before another GPU is available with superior performance and cost-efficiency levels.
The H200 addresses the key compute efficiency issues of the H100, meaning that you will get higher memory bandwidth at a lower performance-per-watt.
The NVIDIA H200 GPU is now fully deployed by DataCrunch, available as 1x, 2x, 4x, and 8x instances, as well as dedicated clusters. This flexibility allows you to tailor your deployments to match your AI and HPC workloads, whether you need a single instance for smaller tasks or an entire cluster for large-scale training and inference.
Ready to take the H200 for a test drive? Spin up a instance today!