
Auf der NVIDIA GTC 2024 bekamen wir einen Vorgeschmack auf die nächste Generation von Hochleistungs-GPUs mit der Ankündigung der Blackwell-Architektur.
Lassen Sie uns durchgehen, was die Blackwell-Architektur aus der Perspektive von KI-Trainings- und Inferenz-Anwendungsfällen bieten wird und wie sie sich mit den besten derzeit auf dem Markt befindlichen NVIDIA GPUs, der A100, H100 und H200, vergleichen lässt.
NVIDIA Blackwell Architektur
Die Blackwell-GPU wurde mit dem spezifischen Ziel entwickelt, generative KI-Workflows in Rechenzentren zu bewältigen. Architektonisch kombinieren Blackwell-GPUs zwei reticle-begrenzte Chips zu einer einzigen, einheitlichen GPU mit einer 10-Terabyte-pro-Sekunde-Chip-zu-Chip-Schnittstelle.
NVIDIA hat seine neueste Generation von Hochleistungs-GPU-Architekturen zu Ehren des amerikanischen Mathematikers und Statistikers David H. Blackwell benannt.
Die Blackwell-GPU ist die größte jemals gebaute GPU mit über 208 Milliarden Transistoren. Sie enthält auch bedeutende Software-Weiterentwicklungen, darunter die zweite Generation der Transformer Engine und Confidential Computing-Funktionen, die die verschlüsselte Nutzung von generativem KI-Training, Inferenz und föderiertem Lernen in Unternehmen unterstützen sollen.
Was können wir von der Blackwell-Architektur erwarten?
5. Generation NVLink:
2-fache Leistung im Vergleich zur vorherigen NVLink-Generation und die Möglichkeit, bis zu 576 GPUs in einem NVLink-Setup zu verbinden.
Confidential Computing:
Neue Verschlüsselungsfunktionen und die Fähigkeit, schneller vertrauliches KI-Training und Inferenz durchzuführen.
2. Generation Transformer Engine:
NVIDIA plant ein großes Update der Transformer Engine-Bibliothek, einschließlich TensorRT-LLM und Nemo Frameworks.
Decompression Engine:
Neuer Workflow kann Daten mit einer Rate von bis zu 800 GB/s dekomprimieren, um beschleunigte Datenwissenschaft und Analytik zu unterstützen.
RAS Engine:
Neue Zuverlässigkeits-, Verfügbarkeits- und Wartungs-Engine (RAS), um potenzielle Fehler zu identifizieren und zu diagnostizieren.
Erweiterte Netzwerktechnologie:
Geschwindigkeiten von bis zu 400 GB/s mit Quantum-2 InfiniBand und Spectrum X Ethernet.
HGX B100 und HGX B200
NVIDIA plant, Blackwell-GPUs mit zwei verschiedenen HGX KI-Supercomputing-Formfaktoren, dem B100 und B200, zu veröffentlichen. Während diese viele der gleichen Komponenten teilen werden, wird der B200 eine höhere maximale thermische Verlustleistung (TDP) und insgesamt eine höhere Leistung bei FP4 / FP8 / INT8 / FP16 / FP32 und FP64 Arbeitslasten haben.
Zum Zeitpunkt der Ankündigung wurde erwartet, dass sowohl der B100 als auch der B200 über denselben 192GB HBM3e-Speicher mit bis zu 8 TB/s Speicherbandbreite verfügen werden.
Spezifikationen von HGX B200 und HGX B100
Spezifikation | HGX B200 | HGX B100 |
|---|---|---|
Blackwell GPUs | 8 | 8 |
FP4 Tensor Core | 144 PFLOPS | 112 PFLOPS |
FP8/FP6/INT8 | 72 PFLOPS | 56 PFLOPS |
Schneller Speicher | Bis zu 1,5 TB | Bis zu 1,5 TB |
Gesamtspeicherbandbreite | Bis zu 64 TB/s | Bis zu 64 TB/s |
Gesamt-NVLink-Bandbreite | 14,4 TB/s | 14,4 TB/s |
FP4 Tensor Core (pro GPU) | 18 PFLOPS | 14 PFLOPS |
FP8/FP6 Tensor Core (pro GPU) | 9 PFLOPS | 7 PFLOPS |
INT8 Tensor Core (pro GPU) | 9 petaOPS | 7 petaOPS |
FP16/BF16 Tensor Core (pro GPU) | 4,5 PFLOPS | 3,5 PFLOPS |
TF32 Tensor Core | 2,2 PFLOPS | 1,8 PFLOPS |
FP32 | 80 TFLOPS | 60 TFLOPS |
FP64 Tensor Core | 40 TFLOPS | 30 TFLOPS |
FP64 | 40 TFLOPS | 30 TFLOPS |
GPU-Speicher / Bandbreite | Bis zu 192 GB HBM3e / Bis zu 8 TB/s | Bis zu 192 GB HBM3e / Bis zu 8 TB/s |
Maximale thermische Verlustleistung (TDP) | 1000W | 700W |
Verbindung | NVLink: 1,8 TB/s, PCIe Gen6: 256 GB/s | NVLink: 1,8 TB/s, PCIe Gen6: 256 GB/s |
Hinweis: Alle petaFLOPS und petaOPS sind mit Sparsität, außer FP64, welches dicht ist.
GB200 Grace Blackwell Superchip
Zusätzlich zu den HGX-Formfaktoren hat NVIDIA einen neuen Superchip angekündigt, der zwei Blackwell Tensor Core GPUs und eine NVIDIA Grace CPU kombiniert. Diese Superchips können in Clustern verbunden werden, beispielsweise in einer NVL72-Konfiguration, die 36 Grace CPUs und 72 Blackwell GPUs zu einer massiven GPU verbindet, die 30-mal schnelleres LLM-Inferencing als die H100 liefert.

*Weitere Informationen zu den H100-Spezifikationen und -Leistungen finden Sie hier.
Blackwell vs Hopper Vergleich
Vor dem Start der Blackwell-Generation von GPUs hat NVIDIA Benchmark-Vergleiche mit der Hopper-Architektur veröffentlicht.
Beim Training großer Modelle (wie GPT-MoE-1.8T) ist die B200 3-mal schneller als die H100.
Die B200 erreicht auch bis zu 15-mal höhere Inferenz-Leistungen im Vergleich zur H100 bei der Verwendung großer Modelle wie GPT-MoE-1.8T.
Denken Sie daran, dass die Hopper-Architektur vor der Veröffentlichung der Blackwell-Serie ein ernsthaftes Upgrade in Form der H200-Spezifikationen erhalten wird.
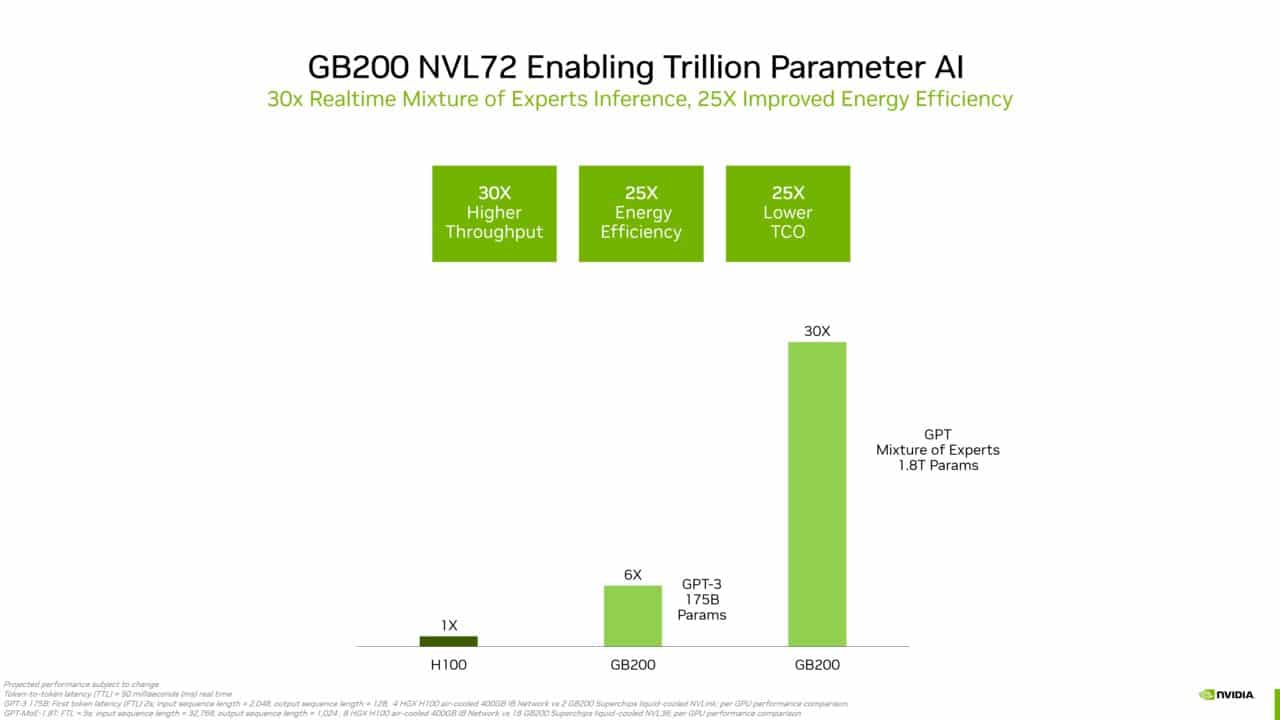
GB200 vs H100 Benchmarks
NVIDIA hat Benchmark-Daten veröffentlicht, die den GB200 Superchip mit der NVIDIA H100 vergleichen.
Der GB200 wird bei ressourcenintensiven Anwendungen eine 30-mal höhere Geschwindigkeit im Vergleich zur H100 aufweisen.
Die Cadence SpectreX-Simulationen sollen auf dem GB200 13-mal schneller laufen als auf der H100.
Der GB200 soll bis zu 25-mal energieeffizienter sein, was zu 25-mal niedrigeren Gesamtkosten im Vergleich zur H100 führt.
NVIDIA B200 vs. AMD MI300X
Ein weiterer wichtiger Vergleichspunkt ist mit dem kürzlich von AMD veröffentlichten MI300X. Während NVIDIA eine sehr klare Führungsposition auf dem Markt für KI-fokussierte GPUs hat, haben AMD und andere große Akteure konkurrierende Produkte auf den Markt gebracht.
Während der MI300X bereits heute auf dem Markt verfügbar ist, wird der beste Vergleich wahrscheinlich mit der B200 sein, da beide Hochleistungs-GPUs bis Anfang 2025 stärker verfügbar sein werden.
NVIDIA B200 | AMD MI300X | |
GPU-Speicher | 192 GB | 192 GB |
Speichertyp | HBM3e | HBM3 |
Spitzen-Speicherbandbreite | 8 TB/s | 5,3 TB/s |
Verbindung | NVLink: 1,8 TB/s, PCIe Gen6: 256 GB/s | PCIe Gen5: 128 GB/s |
Maximale thermische Verlustleistung (TDP) | 1000W | 750W |
Natürlich kann man NVIDIA- und AMD-GPUs nicht nur anhand der Hardware-Spezifikationen vergleichen. NVIDIA hat immer noch einen großen Vorsprung, wenn es um Software geht, da viele KI-Ingenieure es schwierig finden, von CUDA und anderen Frameworks wegzukommen.
Verfügbarkeit und Preisgestaltung
Erwarten Sie nicht, in absehbarer Zeit Zugang zu diesen Hochleistungsgeräten zu erhalten. Das früheste Datum, an dem die B100 verfügbar sein könnte, ist Q4 2024, und die B200 wird wahrscheinlich nicht vor 2025 erhältlich sein. Für die GB200 wurde kein Veröffentlichungsdatum bekannt gegeben.
Außerdem hat NVIDIA keine Preisinformationen veröffentlicht.
Sie müssen nicht warten, um Zugang zu Hochleistungs-GPUs zu erhalten. DataCrunch bietet eine breite Palette an erstklassigen NVIDIA-GPUs zu wettbewerbsfähigen Preisen. Sehen Sie sich die neuesten Cloud-GPU-Preise und die Verfügbarkeit an.
Fazit zur Blackwell-Architektur
Der Wettbewerb im GPU-Rennen nimmt zu und NVIDIA ruht sich nicht auf seinen Lorbeeren aus. Eine frühe Veröffentlichung der Spezifikationen für die Blackwell-Architekturserie bestätigt, dass NVIDIA Ihnen heute und in den kommenden Jahren die leistungsstärksten GPUs bieten wird.
Es kann eine Weile dauern, bis Sie Zugang zur B100, B200 oder GB200 erhalten, aber wenn sie verfügbar sind, können Sie erwarten, dass DataCrunch Ihnen schnellen Zugang, faire Preise und umfassende Leistungsbenchmarks bietet.