
The NVIDIA V100 is a legendary piece of hardware that has earned its place in the history of high-performance computing. Launched in 2017, the V100 introduced us to the age of Tensor Cores and brought many advancements through the innovative Volta architecture.
However, in recent years, the landscape of AI hardware has continued to evolve. Newer models such as the NVIDIA A100 and H100 have entered the market, offering superior performance and capabilities. This raises an important question for AI engineers: what is the best use for the V100 in today’s diverse GPU landscape? Let’s answer this question looking through V100 specs, performance and pricing from today’s perspective.

Introduction to the V100
The NVIDIA V100, launched in May 2017, marked a significant milestone in the GPU industry. It was the first GPU based on NVIDIA's Volta architecture, which introduced several groundbreaking technologies designed to accelerate AI and high-performance computing (HPC) workloads. The V100 was a successor to the P100, bringing substantial improvements in both performance and efficiency.
Volta Architecture
The V100 is built on the Volta architecture, which represents a major leap forward from previous generations. Volta's design focuses on improving parallel processing capabilities and improving energy efficiency. Key features include a new streaming multiprocessor (SM) architecture, a redesigned memory hierarchy, and the introduction of Tensor Cores.
Tensor Cores
One of the key aspects of the V100 is its inclusion of Tensor Cores, specialized hardware designed to accelerate tensor operations essential for deep learning. Tensor Cores enable mixed-precision computing, allowing the V100 to perform matrix multiplications at unprecedented speeds. This results in significant performance boosts for tasks like neural network training and inference.
Power Consumption and Thermal Design
With a TDP of 300 Watts, the V100 is designed to deliver high performance while maintaining energy efficiency. The GPU's cooling solutions are designed to manage this power consumption effectively, ensuring stable operation even under heavy computational loads.
Key V100 Specifications
At the time of its introduction, the V100 was the most advanced GPU in the World. While it has been overtaken in specifications by many newer models, it still has solid specifications capable of high-performance computing.
Here is a spec sheet of what you can expect to find from the V100 GPU:
CUDA Cores: 5,120
Tensor Cores: 640
Base Clock Speed: 1,215 MHz
Boost Clock Speed: 1,380 MHz
Memory: 16 GB or 32GB HBM2
Memory Bandwidth: 900 GB/s
TDP (Thermal Design Power): 300 Watts
How the V100 Compares to the P100
As the first ever GPU to feature Tensor Cores, it’s difficult to evaluate the V100 against earlier models. However, the most natural comparison is with the P100 utilizing Pascal architecture. Compared to the P100, the V100 brought in a sizable increase in CUDA Cores (5,120 vs 3,584) and a substantial increase in memory bandwidth (900 GB/s vs. 720GB/s.)
Thanks to the Tensor Core technology, the V100 was the world’s first GPU to break the 100 teraFLOPS (TFLOPS) barrier of deep learning performance. According to NVIDIA benchmarks, the V100 can perform deep learning tasks 12x faster than the P100.
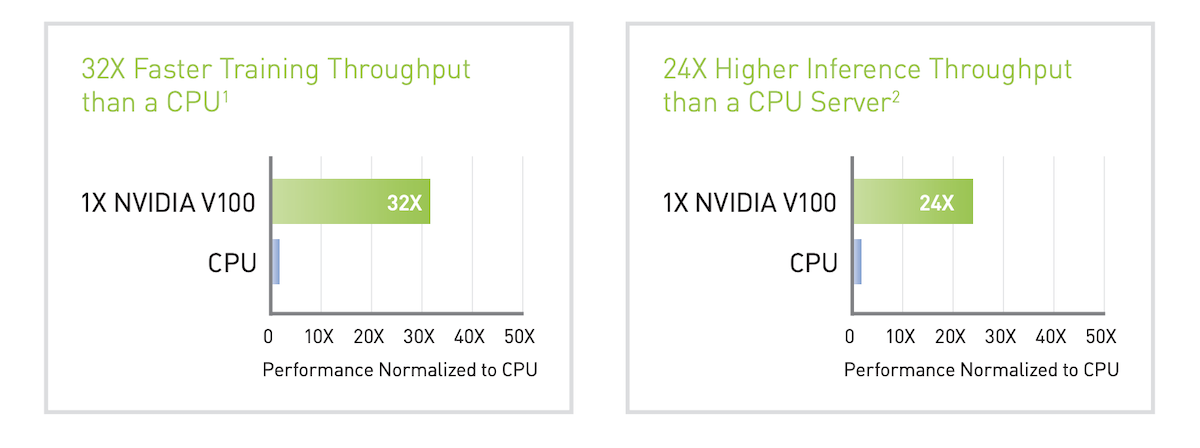
At the time of launch NVIDIA also made a point of comparing V100's AI training and inference performance compared to a Intel Gold [email protected]/3.9Hz Turbo CPU.
A100 Datasheet Comparison vs V100 and H100
Today the more natural comparison is with the A100 and H100 specs. In this comparison, the V100 falls short on many key elements.
GPU Features | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|---|
GPU Board Form Factor | SXM2 | SXM4 | SXM5 |
SMs | 80 | 108 | 132 |
TPCs | 40 | 54 | 66 |
FP32 Cores / SM | 64 | 64 | 128 |
FP32 Cores / GPU | 5020 | 6912 | 16896 |
FP64 Cores / SM (excl. Tensor) | 32 | 32 | 64 |
FP64 Cores / GPU (excl. Tensor) | 2560 | 3456 | 8448 |
INT32 Cores / SM | 64 | 64 | 64 |
INT32 Cores / GPU | 5120 | 6912 | 8448 |
Tensor Cores / SM | 8 | 4 | 4 |
Tensor Cores / GPU | 640 | 432 | 528 |
Texture Units | 320 | 432 | 528 |
Memory Interface | 4096-bit HBM2 | 5120-bit HBM2 | 5120-bit HBM3 |
Memory Bandwidth | 900 GB/sec | 1555 GB/sec | 3.35 TB/sec |
Transistors | 21.1 billion | 54.2 billion | 80 billion |
Max thermal design power (TDP) | 300 Watts | 400 Watts | 700 Watts |
* see detailed comparisons of V100 vs A100 and A100 vs H100.
V100 Performance Metrics
The V100 is still a solid performer in various performance metrics, making it suitable for both training and inference of deep learning models:
FP32 (Single-Precision) Performance: 15.7 TFLOPS
FP64 (Double-Precision) Performance: 7.8 TFLOPS
These metrics highlight the V100's versatility, allowing it to deliver high performance for a range of precision levels required by different AI applications.
Limitations of the V100
The major disadvantage of the V100 is that it does not support BF16 (or bfloat16) data type. This makes it difficult to train today's larger models with the V100. Still, the V100 has it’s use in both inference and fine-tuning, as it has good availability at comparatively low cost compared to newer GPUs.
V100 Use Cases Today
The V100 has been widely adopted in various industries and applications. Here are a few examples:
Deep Learning Training: You can still use the V100 for training of smaller deep learning models, especially ones that don’t require BF16 precision support.
Inference Tasks: The V100's ability to handle high-throughput inference tasks makes it suitable for deploying trained models in production environments.
High-Performance Computing: Beyond AI, the V100 can be used in scientific computing, simulations, and other HPC applications due to its double-precision performance.
Famously OpenAI (with support from Microsoft) used 10,000 V100s to train the GPT-3 language model.
NVIDIA V100 Pricing
Today you can find the NVIDIA V100 offered as individual instances as well as clusters of up to 8 NVLink connected GPUs. In recent years the price of the V100 has gone down, meaning that you can get on-demand from Cloud GPU providers like DataCrunch based on your unique needs and requirements.
In a recent review of Cloud GPU pricing, we found that the cost difference between hyperscalers such as Amazon AWS, Google Cloud Platform and Microsoft Azure was up to 8 times greater than independent AI-computing specialists such as DataCrunch.
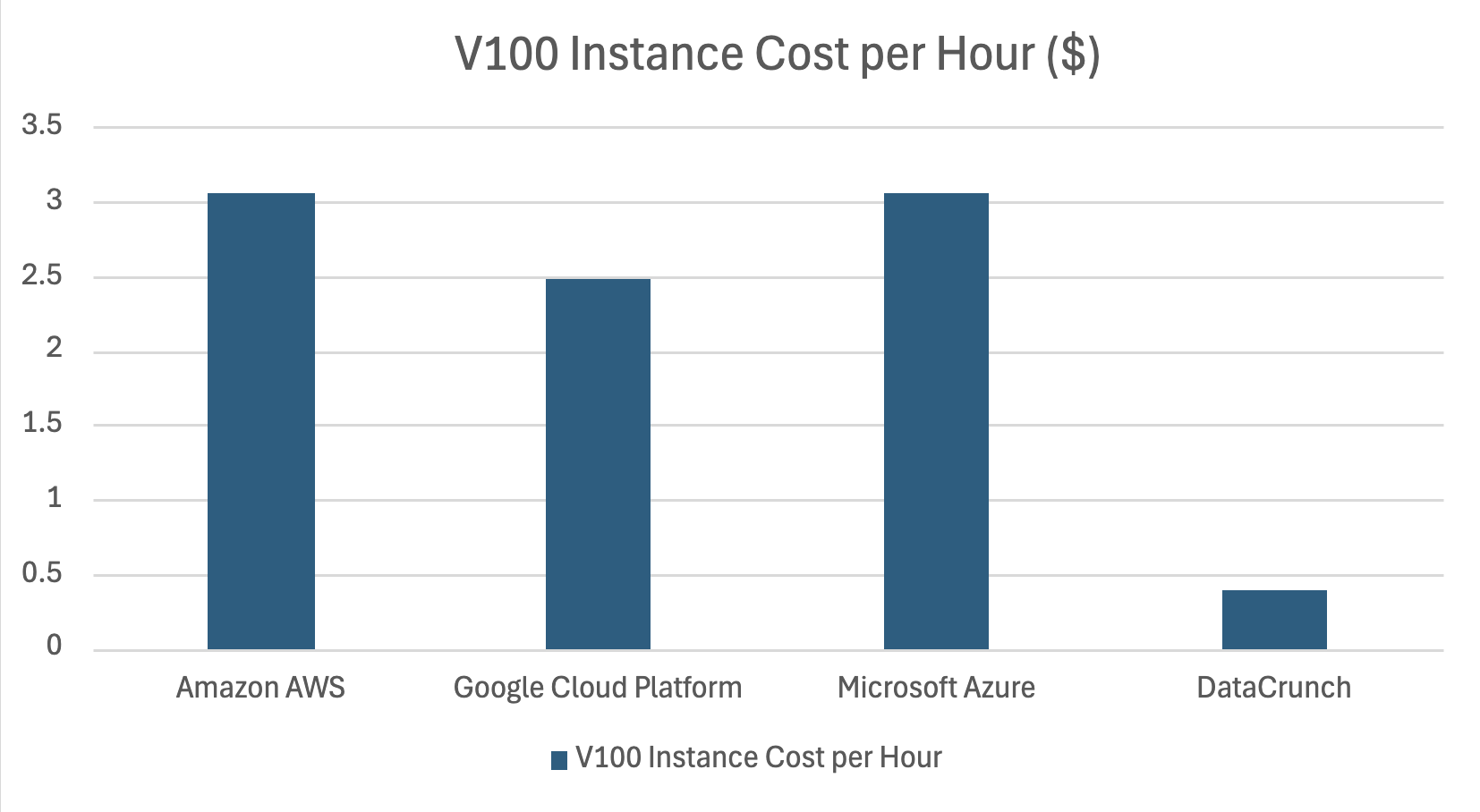
Current on-demand prices of A100 instances at DataCrunch:
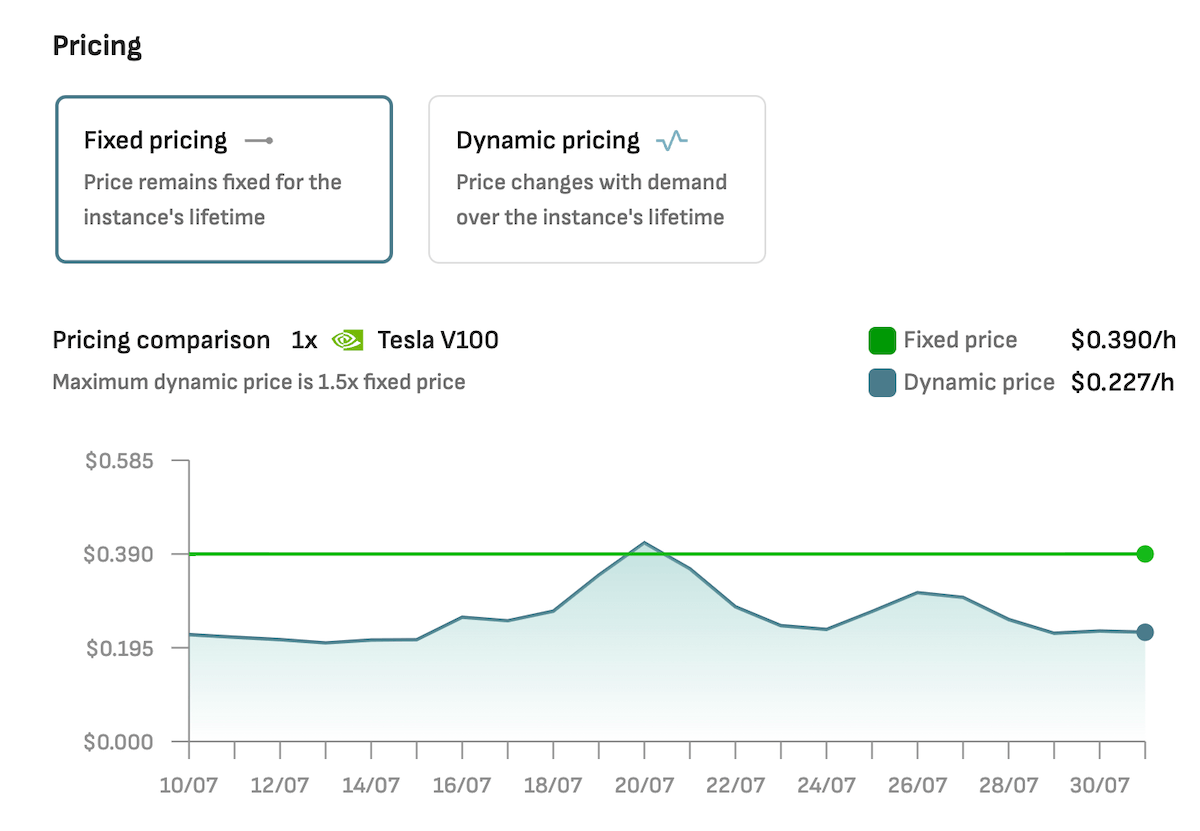
1 x V100 16GB: $0.39/hour
4 x V100 16GB: $1.56/hour
8 x V100 16 GB: $3.12/hour
* see real-time pricing for V100.
Bottom line on the V100
The V100 is a legendary GPU with a deserved place among the most influential pieces of hardware in the development of artificial intelligence.
While it has been overshadowed by newer models, like the A100 and the H100, the V100 remains today a cost-efficient solution for operations like inference and fine-tuning of AI models. See three creative use-cases for the V100 today.
If you’re looking to try out the V100, spin up an instance with DataCrunch today.