
Während viele AI-Ingenieure ihre Aufmerksamkeit auf neuere GPUs verlagert haben, bleibt die NVIDIA A100 heute ein leistungsstarker und effizienter Beschleuniger für maschinelle Lernprojekte und Inferenzprojekte.
Die A100 hat eine solide Erfolgsbilanz und ist nach wie vor äußerst nützlich für viele Hochleistungs-Workloads. Sie hat auch eine bessere Verfügbarkeit in On-Demand-Cloud-GPU-Instanzen als viele neuere Modelle. Sehen Sie sich eine detaillierte Überprüfung der A100-Spezifikationen, Preise und Konfigurationsoptionen an. Wenn Sie daran denken, eine A100-Instanz hochzufahren, müssen Sie den Unterschied zwischen den A100 40GB- und 80GB-Modellen sowie den Leistungsunterschied zwischen den PCIe- und SXM-Optionen kennen. Lassen Sie uns diese Formfaktoren im Detail durchgehen.

Was ist PCIe?
PCIe (Peripheral Component Interconnect Express) ist ein Hochgeschwindigkeitsschnittstellenstandard, der verwendet wird, um verschiedene Hardwarekomponenten mit dem Motherboard eines Computers zu verbinden. PCI wurde ursprünglich von Intel entwickelt und 1992 eingeführt, und PCIe (wobei "e" für Express steht) im Jahr 2003.
PCIe arbeitet mit Lanes, das sind Paare von Drähten, die Daten zwischen dem Motherboard und dem Peripheriegerät übertragen. Jeder PCIe-Steckplatz kann mehrere Lanes haben (x1, x4, x8, x16 usw.), wobei x16 am häufigsten für GPUs verwendet wird und die höchste Bandbreite bietet.
Die NVIDIA A100 verwendet PCIe Gen4 mit 64GB/s Bandbreite in einer x16-Konfiguration.
Was ist SXM?
SXM ist ein benutzerdefinierter Sockel-Formfaktor, der von NVIDIA speziell für Hochleistungsrechnen und intensive maschinelle Lernaufgaben entwickelt wurde. Ursprünglich mit den P100-GPUs im Jahr 2016 eingeführt, bietet es eine höhere Dichte und Leistung durch eine engere Integration der GPUs mit der Systemplatine.
SXM steht für Server PCI Express Module. Es ist darauf ausgelegt, mit den NVLink-Verbindungen von NVIDIA für die direkte GPU-zu-GPU-Kommunikation mit höherer Bandbreite, bis zu 600GB/s pro Verbindung, zu arbeiten. Bis zu 8 GPUs können in einer einzigen SXM-Platine verbunden werden.
DataCrunch verwendet ausschließlich SXM-Technologie in der A100- und H100-GPU-Serie.
A100 PCIe vs SXM4 Datenblatt
Merkmal | A100 PCIe | A100 SXM4 |
|---|---|---|
Formfaktor | PCIe | SXM |
Speicherbandbreite | 1.935 GB/s | 2.039 GB/s |
Maximale thermische Verlustleistung | 250W | 400W |
GPU-Speicher | 40GB | 40GB oder 80GB |
Verbindung | - NVLink-Bridge für bis zu 2 GPUs: 600 GB/s - PCIe Gen4 64 GB/s | - NVLink: 600 GB/s - PCIe Gen4 64 GB/s |
Multi-Instance GPU (MIG) | Bis zu 7 MIGs @ 5GB | Bis zu 7 MIGs @ 10GB |
Bei der Betrachtung der Implikationen der PCIe- und SXM-Formfaktoren für maschinelle Lern- und Inferenzprojekte spielen mehrere Schlüsselfaktoren eine Rolle, darunter Leistung, Skalierbarkeit, Energieeffizienz und Systemintegration.
Leistung und Geschwindigkeit
Der SXM-Formfaktor bietet im Allgemeinen eine höhere Leistung im Vergleich zu PCIe aufgrund seiner überlegenen Bandbreiten- und Leistungskapazitäten. SXM-GPUs, wie die NVIDIA A100 SXM, bieten eine höhere Speicherbandbreite (z.B. 2.039 GB/s im Vergleich zu 1.935 GB/s bei PCIe-Versionen) und eine höhere thermische Verlustleistung (TDP), was intensivere Rechenaufgaben ohne thermische Drosselung ermöglicht. Das bedeutet, dass der SXM-Formfaktor für groß angelegtes maschinelles Lernen, das oft die schnelle Bewegung großer Datenmengen erfordert, eine schnellere Datenübertragung und eine bessere Handhabung komplexer Modelle liefern kann, was zu verkürzten Trainingszeiten führt.
SXM4 und PCIe im MLPerf-Benchmark
Um die Leistungslücke zwischen den SXM4- und PCIe-Formfaktoren zu veranschaulichen, haben wir deren Leistung anhand des MLPerf-Trainings Benchmarks für maschinelles Lernen bewertet. Wir trainierten drei Modelle:
Das PLM BERT-Large,
Das ResNet v1.5 Vision-Modell und
Das Mask R-CNN Objekt-Erkennungsmodell.
Für alle Aufgaben verwendeten wir Konfigurationen mit 8 GPUs, die jeweils mit 80 GB Speicher ausgestattet waren.
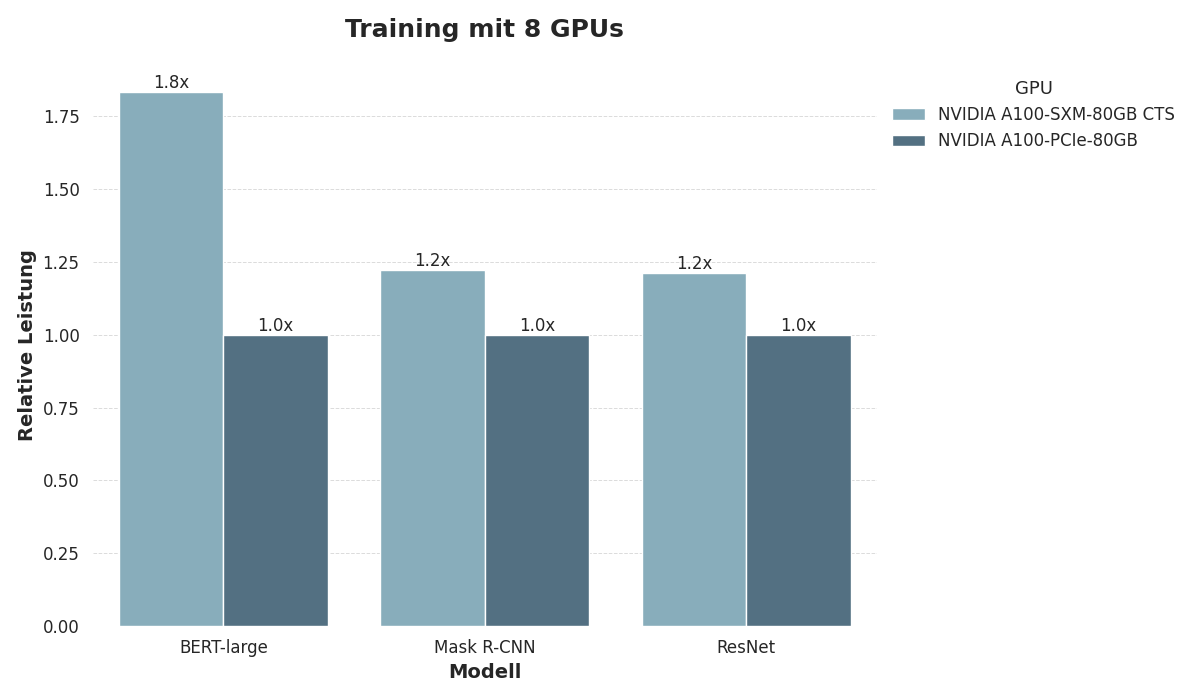
Die Ergebnisse zeigen, dass SXM4 beim Training von BERT-Large einen deutlichen Leistungsvorteil bietet, da das Training mit PCIe fast doppelt so lange dauert wie das Training mit SXM4. Die Leistung ist wesentlich ausgeglichener beim Training der Vision-Modelle ResNet und MASK R-CNN.
Skalierbarkeit und Multi-GPU-Konfigurationen
SXM-GPUs sind so konzipiert, dass sie nahtlos in hochdichten Multi-GPU-Konfigurationen arbeiten. Sie nutzen die NVLink- und NVSwitch-Technologien von NVIDIA, die eine direkte, hochbandbreite GPU-zu-GPU-Kommunikation ermöglichen (bis zu 600 GB/s pro Verbindung). Dies ist besonders vorteilhaft für verteiltes Training großer neuronaler Netze, bei dem mehrere GPUs schnell Daten austauschen müssen. Im Gegensatz dazu unterstützen PCIe-GPUs, obwohl sie NVLink-Brücken verwenden können, typischerweise weniger GPUs mit geringerer Bandbreite, was in Multi-GPU-Setups zu einem Engpass werden kann. Daher bieten SXM-GPUs für groß angelegte maschinelle Lernprojekte, die umfangreiche Parallelverarbeitung erfordern, überlegene Skalierbarkeit und Leistung.
Energieeffizienz und Wärmemanagement
Die höhere TDP von SXM-GPUs (bis zu 500W in kundenspezifischen Konfigurationen) ermöglicht es ihnen, höhere Leistungsstufen über längere Zeiträume aufrechtzuerhalten. Dies ist entscheidend für intensive Trainingssitzungen, die Tage oder Wochen dauern können. Die fortschrittlichen Kühllösungen, die typischerweise mit SXM-Modulen verbunden sind, wie z.B. ausgeklügelte Flüssigkeitskühlsysteme, gewährleisten, dass diese GPUs effizient arbeiten, ohne zu überhitzen. Andererseits sind PCIe-GPUs mit ihren zugänglicheren luftgekühlten oder einfacheren flüssigkeitsgekühlten Designs unter anhaltend hoher Last möglicherweise anfälliger für thermische Drosselung.
Systemintegration und Flexibilität
PCIe-GPUs bieten im Allgemeinen mehr Flexibilität und sind einfacher in bestehende Systeme zu integrieren, was für kleinere oder weniger spezialisierte maschinelle Lernprojekte von Vorteil ist. Sie können zu Standard-Workstations oder -Servern hinzugefügt werden, ohne dass umfangreiche Änderungen oder spezialisierte Infrastrukturen erforderlich sind. Dies macht PCIe-GPUs zu einer praktischen Wahl für Organisationen, die ihre Rechenkapazitäten schrittweise aufrüsten möchten.
Wenn Sie jedoch auf hochleistungsfähige maschinelle Lernanwendungen fokussiert sind, kann sich eine Investition in SXM-basierte Systeme durch die erheblichen Leistungssteigerungen und die Fähigkeit, komplexere und größere Datensätze effizient zu verarbeiten, rechtfertigen.
A100 PCIe oder SXM4 für Training und Inferenz?
Für das Training großer Modelle, insbesondere solcher, die tiefes Lernen und neuronale Netze umfassen, führen die verbesserte Bandbreite, Leistung und Konnektivität der SXM-GPUs zu schnelleren Konvergenzzeiten und der Fähigkeit, größere Batch-Größen zu verarbeiten. Dies kann den gesamten Entwicklungszyklus beschleunigen und es den Forschern ermöglichen, schneller zu iterieren.
Während der Inferenz, bei der die Echtzeitleistung kritisch ist, können die geringere Latenz und der höhere Durchsatz der SXM-GPUs erhebliche Vorteile bieten, insbesondere in Umgebungen, in denen Inferenz auf großen Datensätzen oder komplexen Modellen durchgeführt werden muss.
Fazit zu A100 PCIe vs SXM
Während PCIe-GPUs Flexibilität und einfache Integration bieten, liefern SXM-GPUs überlegene Leistung, Skalierbarkeit und Effizienz für maschinelles Lernen und Inferenz. Die Wahl zwischen den beiden hängt weitgehend vom Umfang und den Anforderungen der maschinellen Lernprojekte ab, wobei SXM die bevorzugte Option für groß angelegte, hochleistungsfähige Aufgaben ist, und PCIe für kleinere, flexiblere Einsätze geeignet ist.
Bei DataCrunch verwenden wir ausschließlich den überlegenen SXM4-Formfaktor in all unseren A100- und H100-On-Demand-Instanzen und -Clustern. Erleben Sie selbst die Auswirkungen auf die rohe Rechenleistung und Geschwindigkeit, indem Sie noch heute Ihre eigene Instanz einrichten.