
Imagine a powerhouse GPU that's designed to turbocharge the most demanding tasks in artificial intelligence, machine learning, and high-performance computing - enter the NVIDIA RTX 6000 ADA. Built on the revolutionary Ampere architecture, this mighty GPU boasts a dynamic duo of Tensor cores and CUDA cores, working in harmony to unlock jaw-dropping performance levels for a wide range of AI and machine learning applications.
It's armed with advanced AI capabilities like deep learning and neural network processing, ready to tackle the most complex challenges. The NVIDIA RTX 6000 ADA plays well with a plethora of AI and machine learning frameworks, libraries, and tools, empowering researchers and developers to unleash its full potential in their cutting-edge projects.
NVIDIA's Ada Lovelace Architecture, designed for AI applications, offers unprecedented performance and efficiency. Combining third-gen RT Cores, fourth-gen Tensor Cores, and next-gen CUDA cores, it revolutionizes artificial intelligence workload capacity. The RTX 6000 ADA harnesses CUDA cores for significant performance boost, with 18,176 cores compared to its predecessor's 10,752. Third-gen RT Cores and Tensor Cores accelerate AI and deep learning tasks.
RTX 6000 ADA vs other Cards
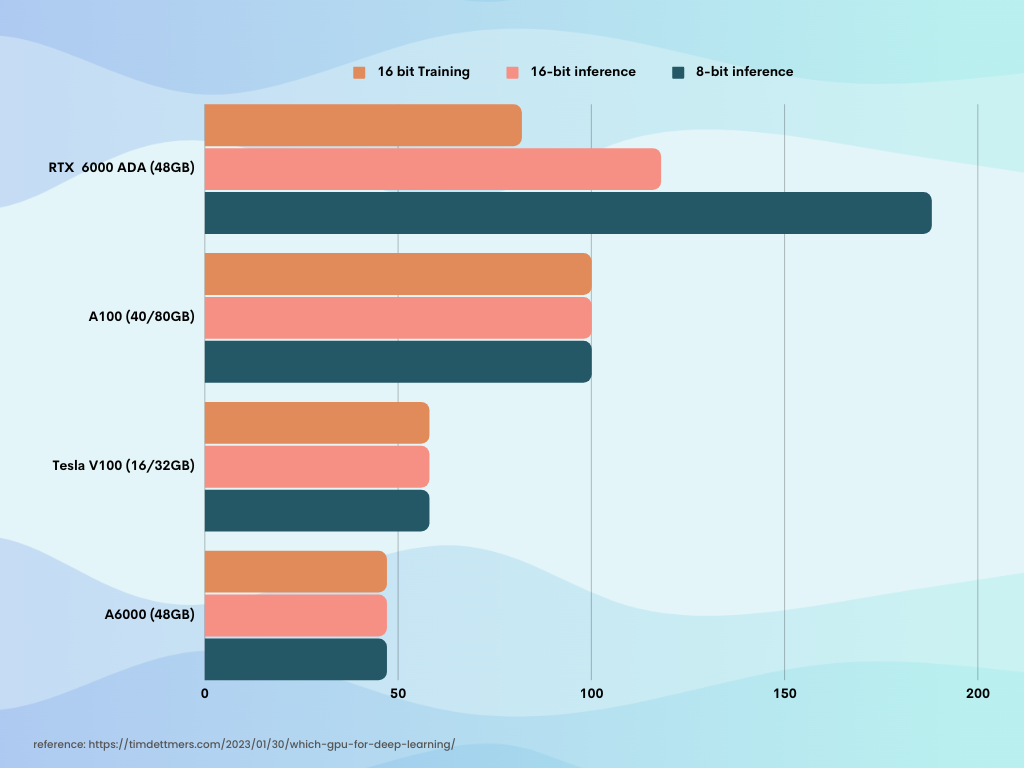
Looking at the comparison chart below, it's clear that the three NVIDIA GPUs each have their own strengths and weaknesses. The NVIDIA A100 shines in deep learning performance and AI workloads, while the NVIDIA Tesla V100 is optimized for data center use. The NVIDIA RTX 6000 ADA offers a balance of versatility, performance, and cost-effectiveness, making it a compelling choice for a wide range of applications.
Specifications | RTX 6000 ADA | A6000 | Tesla V100 | A100 |
|---|---|---|---|---|
Architecture | ADA | Ampere | Volta | Ampere |
CUDA Cores | 18176 | 10752 | 5120 | 6912 |
Tensor Cores | 568 | 336 | 640 | 432 |
RT Cores | 142 | 84 | N/A | 72 |
Memory Capacity | 48 GB GDDR6 | 48 GB GDDR6 | 16-32 GB HBM2 | 80 GB HBM2e |
Memory Bandwidth | 960 GB/s | 768 GB/s | 900 GB/s | 2039 GB/s |
Single-precision performance | 91.1 TFLOPS | 38.7 TFLOPS | 15.7 TFLOPS | 19.5 TFLOPS |
RT Core performance | 210.6 TFLOPS | 75.6 TFLOPS | N/A | 312 TFLOPS |
Tensor performance | 1457.0 TFLOPS | 309.7 TFLOPS | 125.0 TFLOPS | 1248.0 TFLOPS |
*See an updated overview of RTX 6000 ADA specs.
Why use DataCrunch for running your RTX 6000 ADA
Pricing model
We make sure you never get hit with unexpected costs. In the world of GPU hosting providers, we offer an ideal combination of reliability and affordability. With a transparent pricing model that utilizes pre-paid credits and clear pricing, you can put aside concerns about hidden or unexpected costs. This allows you to concentrate on what's truly important—growing your business, boosting your AI/ML workloads, and fostering innovation—while keeping your budget well-managed.
Easy to launch and test, no commitments
Where other providers often gate-keep their best hardware. Either behind large payment commitments or enterprise customers only. At DataCrunch, we offer our GPU instances and clusters to anyone who needs the power. Run them as spot-instance, on-demand or long-term for more permanent workloads. All without any limitations normally set by other companies.
Ready made notebooks like Jupyter
Looking to get started without any additional setup? Use our ready made Jupyter Notebook instances. Just a few clicks to get going, they come complete with an introduction course from FastAI.